Imagine that we have a set of states, Then, the idea of a Markov process, is that no matter where we are in the chain of transitions, or no matter how many state transitions we have seen, or what path we have followed to get to this state, given the current state, is determined by with some noise. that is, if , then there are probabilities for each such that . and such transition probabilities are present for each state of .
A nice way to draw a markov process is to draw a directed graph (which may have self loop, but no multi edges) whose vertices are the states and whose edges represent a single step transition from state to state , with a probability weight on that edge. (note that can be different from )
these edge weights could be written as well. We can also enforce a complete directed graph, with all self loops, and put when we can't get from state to state .
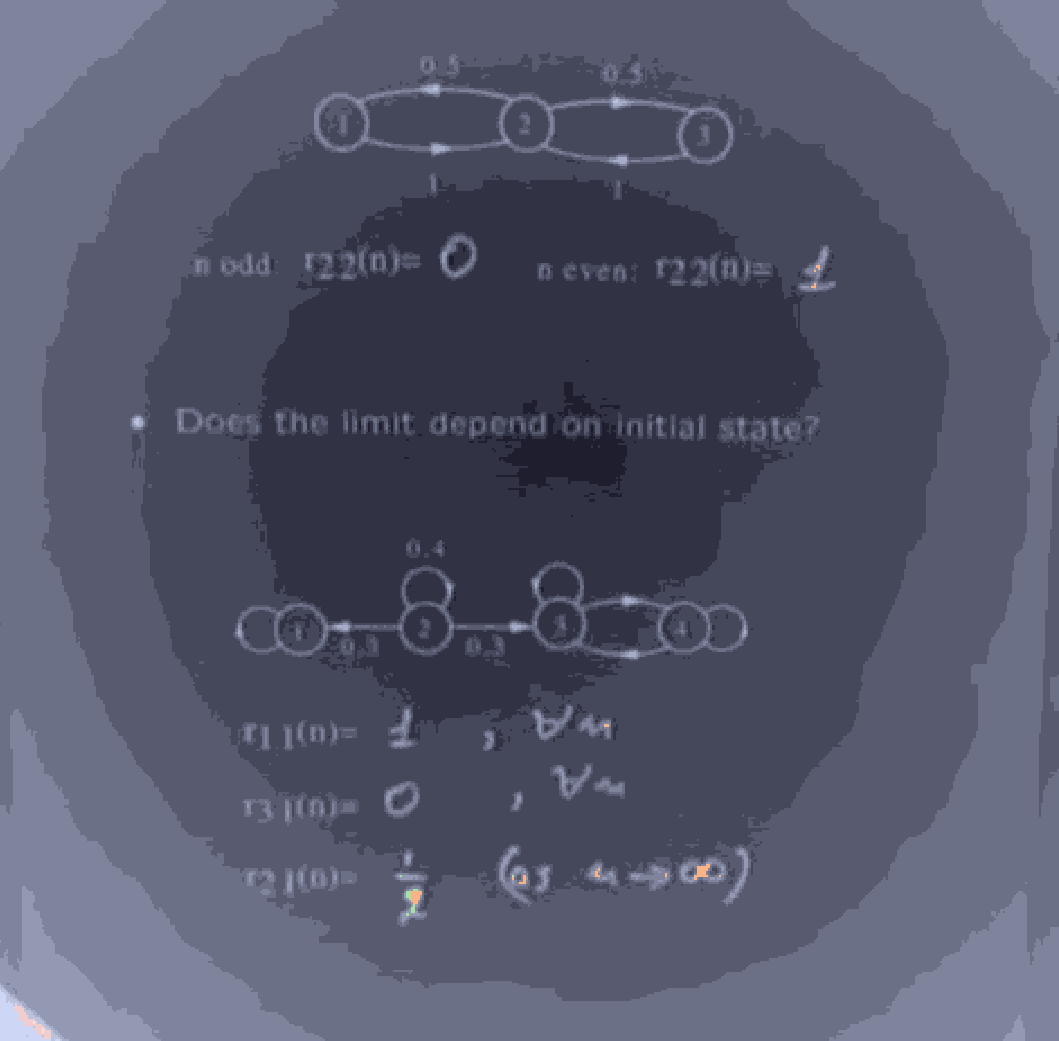
Then, the question is, starting from state , and taking transitions or steps, what is the probability I get to state ?
denote as the probability of starting at state and reaching state after steps.
Then, recursively, using the complete DAG idea, for each state , (ofc state transitions are independent of previous history) we can look at the probabiity of reaching from in states, depicted and then multiply that by the probability of reaching from in one step, and add up the branches for each k.
That is, $$r_{ij}(n) = \sum_{k=1}^mp_{kj} \cdot r_{ik}(n-1)$$
Note that for any state , the probabilities of the outgoing edges to any state (maybe even itself), should add up to one. .
generic limits for as
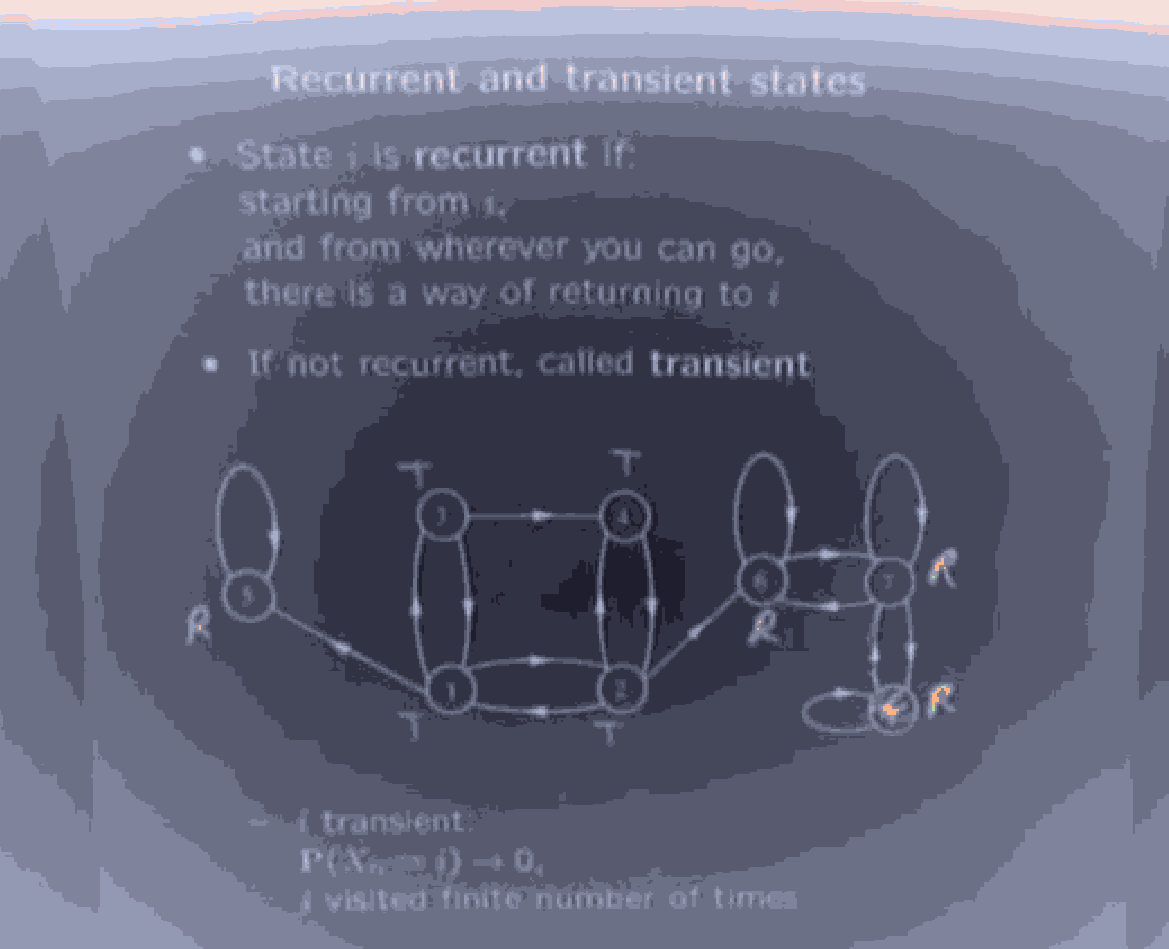
Recurrent and Transient states:
When drawing graphs of Markov chains, it is custom to omit zero probability edges, hence in the graph of the Markov chain, there is a path between two vertices iff there is a non zero probability of reaching (at least in 1 direction) from one state to the other.
A graph is a markov graph if the set of all possible states, and , moreover for any vertex , .
define the relation on , where .
Now, define another relation where if and only if whenever (that is whenever is on some path from ), as well. (that is there is a path from ) back to .
That is is the set of all vertices such that whenever is on some path of , there is also a path from back to . of course this is an equivalence relation, and each equivalence class partitions the vertices into states where once you get there, you stay in the same equivalence class (like two way connected components) So once you're in any , there is no way to reach any
These equivalence classes are called recurrent states.
Notice that is not a full partition, some vertices are NOT in ANY equivalence class under . Such vertices/states are called transient.
Eventually, moving between transient states, we will have to escape into some state, and we can never get back, that is we, will move into some reccurrant class.
if is a transient state, in the long run as .
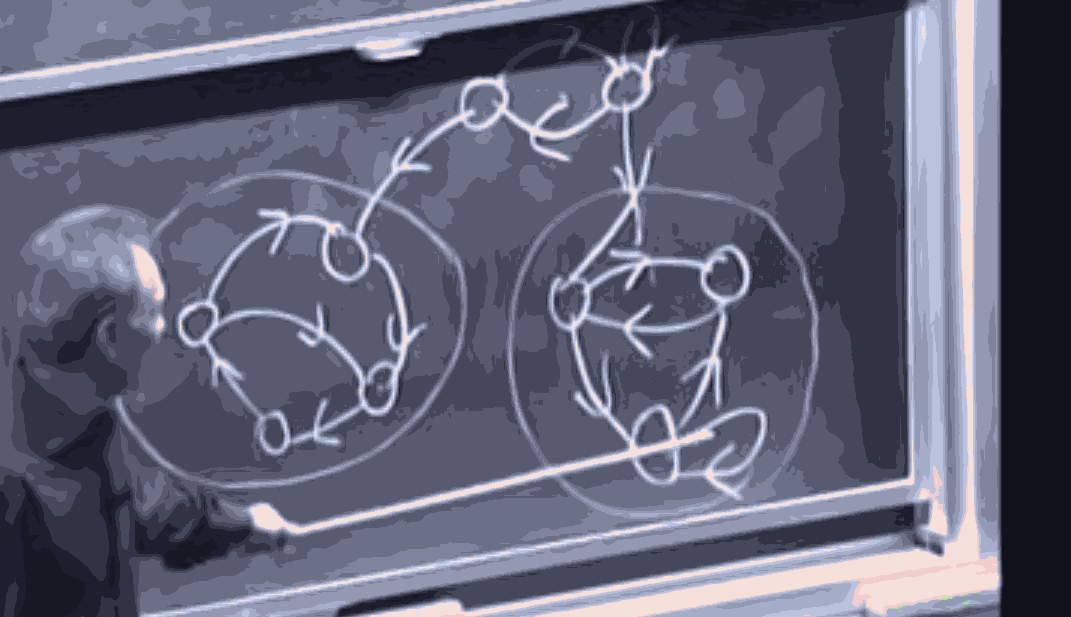
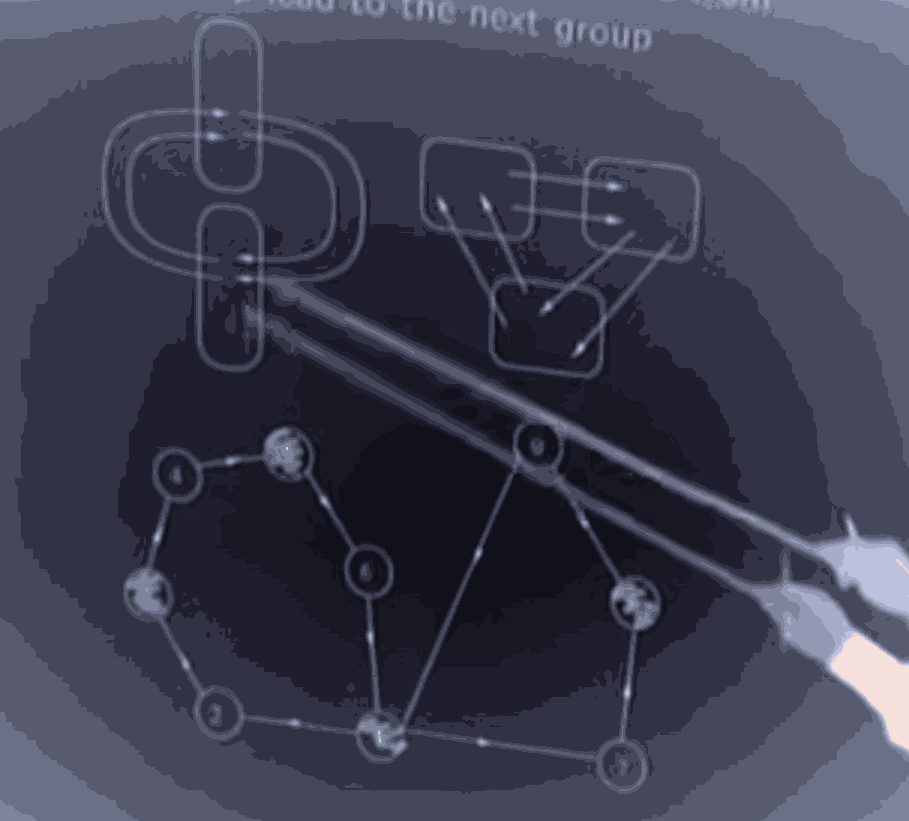
In a general markov chain, you have some reccurant classes of states, with all edges internal, and some transient states that can get to some vertex of some recurrant class (and by definition can never leave)
Periodic markov chains
Suppose is a markov graph, Then is periodic, if can be partitioned into color classes such that there exists an edge from (a vertex in) to if and only if an(d that is the minimum partitioning. (fewest number of classes).
if we have a self loop, the chain is not periodic :)
Steady state Markov theorem:
So before we go on, Let us talk about the matrix interpretation.
so if I have some states and I have some initial random varaible , which encapsulates the distribution for each , then we can write as a vector where and each component is between and of course.
Now, suppose using a the Markov graph , make an matrix where the th entry is the probability edge weight (or zero if that edge is not in G) of the edge (we are reversing the direction here)
That is for each pair .
Why do we reverse the direction? just see below (we just do it to preserve notation of multiplying vectors on the right).
So HWAHT is is ? well as a computation, $$M\mathbf{v_{0}}^i = \sum_{k=1}^m M[i][k] \mathbf{v_{0}}^k$$
Hence, the th entry of , can be seen as:
Probabalistically, we can say $$ P(X_{1} = i) = \sum_{k=1}^m p_{ki} P(X_{0} = k)$$
So The above thing looks like the total probability theorem right? probability that is the sum of the disjoint probabilities that: given , what is the probability that ? the conditional becomes multiplication due to independence.
Therefore, if is a matrix of a markov graph , where , and The initial random variable is represented by the distribution , Then the distribution of is represented by . Inductively, And since markov chains are only determined by the current state, and forget the previous state, we can treat as the intital state, and , to get that is represented by the distribution .
Therefore, using the transition matrix we have that is represented by the distribution .
We sort of want to know if the distribution of the states, after transitions, given by when become very large, approaches a steady distribution , that is independent of the initial choice of
If A markov chain has more than one recurrent class, (and assume is deterministic, that is we choose exactly 1 initial state j, without any uncertainity) if starts at a transient vertex, then with non zero probability, we enter one of (at least 2) recurrent classes, after which we cannot leave it. However if we start at the OTHER recurrent class, we can never enter this one. So the steady state distribution depends on where we start.
A Markov chain that has more than one recurrent class is called "reducible", intuitively, you can think about the fact that given a long time, the distribution settles into one (of the many) recurrent classes and never leaves, so each recurrent class can be treated as a different chain.
A Markov chain is irreducible if there is exactly one recurrent class, and no transient vertices.
So we can turn a transition matrix into an adjacency matrix by just taking the ceiling, so non zero probability means . So the adjacency matrix .
So the nice thing about is that repsents the number of 1 length paths from to , represents two length paths and so on. To determine reachability, it is suffient to compute . and wherever there is a
non zero element make it one, else leave it zero, (there are at most m-1 length paths) to get the reachability matrix
AN aside
NOTE! there are many ways to get an algorithm for the sum , we could repeatedly square and store about powers and for any power , that we want to calculate, we want to write in binary, as , and whichever , we have calculated in our look up table, and we have to multiply all these, doing matrix multiplications for each that we have not calculated. So how many matrix multiplications are we doing to calculate all of ?, well first we do multiplications one for each (roughly, roughly). And then, we have to calculate for each from that is not a power of 2. and each such calculation takes time.
For a rough upper bound, suppose we just do each , without ignoring the powers of two we have already computed.
So we do total matrix multiplies. Which is roughly which is roughly .
So doing matmuls, we might parallelize these matmuls or whatnot. Just saying that its doable and not intractable. And then we have to do matrix additions. which we could also paraellize.
Now that we have the reachability matrix of the markov graph , then is irreducable if and only if is symmetric. This means there is only one reccurent class, as is reachable from if and only if is reachable from .
If we want to impose a stronger notion on irreducible markov chains, as given here. We have said that is irreducible if there is only one recurrent class and no transient vertices. But we can go one step further and say that is irreducible if and only if ANY node is reachable from any other node . That is, the reachability matrix of has one in ALL of its entries.
So there is this process of getting , then , then , then , where gives if else gives . So we want to have all ones, so let us reverse engineer this. This means that has all positive elements.
Which means for every pair there exits such that . So if this is violated, there exists (at least one) pair for which each of have a zero in the th entry, which is easier to work with.
So we will not push on what might look like given these conditions. (at least for now)
Next, given adjacency matrix of Markov chain , we say is periodic, if it is possible to partition vertices of into , such that for any two vertices and , there exists an edge if and only if modulo . (and is the minimal size of any such partition)
Now, there is no harm is assuming that and , and so on. This is just a relabeling of the vertices of , so that each color class has labels that are consecutive. If this re-labeling is given by an isomorphism , then The isomorphic adjacency matrix is given by .
The matrix is particularly cool, as we can partition it into block matrices, Where the block is made by taking the the rows and the columns and intersecting them.
Writing the matrix as blocks like this, we see that the only blocks that can have ones in it are the blocks and all other blocks must be made entirely of zeros. (i will put a picture for this sometime)
A matrix that DOES NOT have this property represents the adjacency of an Aperiodic Markov chain.
Now to state the thoerem: if is a state trasition matrix of markov chain , and is an adjacency matrix of , (both and are allowed to be re-written, as long as they use the same isomorphism on ), then a steady state distribution is one where . If (and hence ) are such that they are irreducible and Aperiodic, then there exists a steady state such that no matter the initial distribution , for any , there exists such that .
As far is I know, is allowed to depend on as well, just that no matter what is, it eventually has to converge (maybe at a different rate than some ) to .
A lot of the ideas we build high on drugs today is refined and tied up to become proofs here. (note that I use a transposed transition matrix, so I can right multiply column vectors the usual way, but the paper does it the other way around)
Finally, if is a markov chain, in states, described by the transition matrix , which contains probabilities as its entries, and that the columns of are normalized (they sum to one), And such that is aperiodic and irreducible, then there exists a unique steady state distribution, which we can solve for by allowing where and the sum of the components of is .
Given the steady state distribution , and observing over a long, long number of transitions, The fraction of times we reach some state is equal (in the limit) to .
And the faction of times we transition from state to state is .