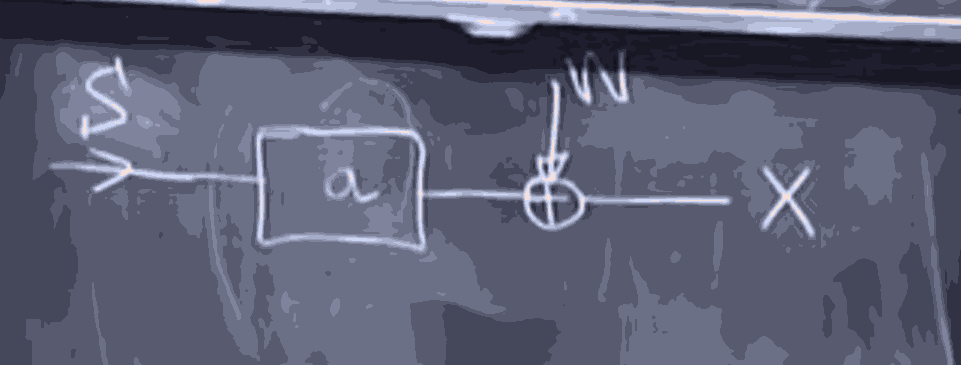
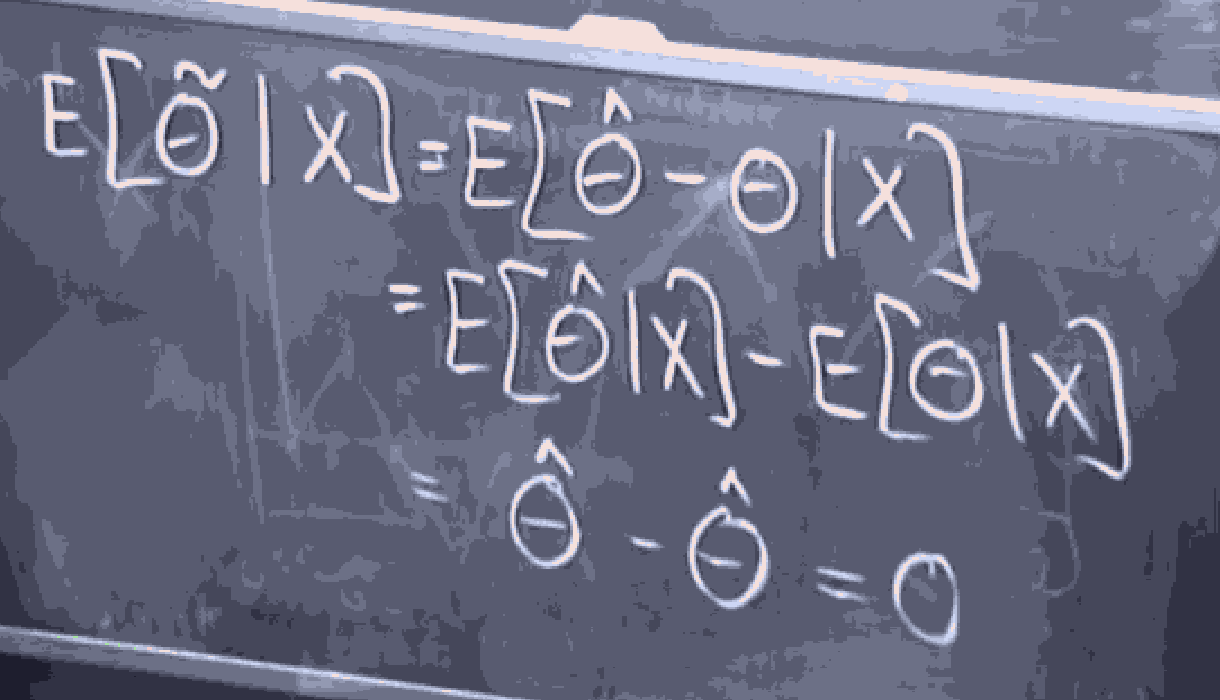So we have some signal going through a box which does something "deterministic", and turns , where is some collection of parameters, and then some sort of noise is applied, to get the final output, So we can say . Where is a process that we actually know. but intead of getting the result directly from , there is some Noise being applied by . (we don't know ).
Then there are two types of inference problems:
Where we can see both and , and use it to estimate the parameters , of the box , dealing with the noise applied by .
Where we know the parameters , And we can measure the output (noisy) signal , and try to figure out what went inside.
So HWEN we have a finite set of possibilities for the unknown, we have to make a decision with least probability of error. (Hypothesis testing)
if the unknown is on a continuum, we aim at a small estimate error. (Estimation)
Let us talk about estimating the mass of electron. Of course the mass of the electron is not a random thing, it is a constant.
Imagine we have a noisy measuring apparatus, that takes in the mass of the electron and gives out a measurement modelled as a random variable .
In classical statistics, The model of the measuring apparatus, is a probability distribution of , which is of course affected by the mass of the electron and some noise. So in classical statistics, we are thinking of measuring apparatus, as simply putting a distribution over the noisy measurement of the mass of the electron.
The Bayesian philosophy is that even though the mass of an electron is constant, what we DONT KNOW, we should put a distribution on it. so is some "prior" distribution on , which if we don't know ANYTHING we might say, all masses of the electron in a certain range are equally likely, or we can put a more sophisticated prior distribution on , based on previous work.
The model of our measurement box, is a distribution of the random variable , given the random variable , with distribution .
The "new and better" random variable that we need to put a distribution on, is actually (posterior distribution), because if we had some "prior" belief on the distribution of , and out measuring box, gives us the distribution of the output data conditioned on the distribution of , We hope that when our prior belief on improves to a better belief, after conditioning it on the output data .
Bayesian hypothesis testing and estimation
So in this picture, is the height of a bird at time . We believe it to be parabolic, and so we want to estimate the coefficients. So we have some prior beliefs on these coefficients (as random variables), and we make measurements at time steps, modelled by the random variable , unfortunately, the measurements are noisy, so we think that is equal to plus some pure noise random variable . And if we have a reasonable idea of what distribution to put on , and hence infer the distribution on , We have all the data, to use the bayes rule, to UPDATE out belief of the distribution on the priors , to the posterior belief (after seeing some data) which has the distribution shown in the above picture.
Least mean square estimation
In the above picture, we have no information more about ,
and we want to estimate it with a single real number .
We can do this by minimized , which using calculus, we get . So if our goal to minimize the expected squared error (or mean squared error) between a random variable and an estimate, we best set the estimate to the mean of the random random variable.
Now, let us introduce some extra information, and say that a measuring device, that noisily measures outputs the random variable .
So then, in the usual Bayesian way, we want an estimate , which is a random variable, that whenever we see that , we think is a good estimate for .
Basically what we are saying, is that given the data , whenever , we want to minimize the posterior error . The function is called an estimator, because based on the random variable , and whatever value we observe from it, it gives an estimate of .
Now, the question is, could there be an estimator of the posterior that has the least mean squared error, no matter what value collapses to?
When, Let us use the arbitrary choice of technique to show that there is global best estimator.
Well, pick arbitrary value that collapses to. In this new (and fixed) conditional universe, we want to minimize . Expanding it out: , Again taking the derivative of wrt to , and setting it equal to zero, we get that the best , is actually just .
So no matter what we pick, for that , the least mean squared estimate for is just .
Which means that for any estimator rv of the unknown , given data , is actually the random variable .
So we have concluded that the best estimator (or bestimator), in the besian setting: of having some unknown , modelleled by the random variable , and some prior distribution , and a noisy measurement modelized by , which outputs measurements, which are modelled by the random variable , where we update out prior distribution on to a better posterior distribution, on using the bayes rule.
So the best estimator in this setting, which minimizes expected squared error between and in the universe conditioned on the random variable , is .
And furthermore, it is not only true that beats out any other (for LMS error) in the universe conditioned on , but it beats out any estimator in general.
That is, for some observed data modelled by , The estimate for itself, in the conditional universe, is a better estimate than any other function on the observed data.
We write this estimator as .
So HWAT IS THE ERROR OF THIS ESTIMATOR? well, its . what is the expected value of this error
The above idea comes from the fact that , hence , (when we give the random variable , is determined, hence its expected value is itself), and also by definition .
So my expected error between the bestimator and the unknown random variable, conditioned on any data, is the random variable . (zero)
That is . Notice that this expectation is actually a function on the random variable . if no matter what you pick, this function takes it to , then the expected value of the error (unconditioned) (the the number 0).
Now, notice that . Hence, no matter what the random variable is, the expected value, (the number zero).
Now for the linear LMS, we assume our estimator to have an affine relationship with the data variable
There is some nice intuitive idea here. Of course, given a prior on , we start with the mean(or expectation) of this prior.
Then, given the data , we look at the covarience of .
If the data we collected has no covariance (covarience is zero) then the data we collected is useless. Hence the mean of the prior is still the best we can do.
if covariance of is positive, they both are bigger than their means, or smaller than theirs means together, respectively. In this case, for some observation if it was bigger than the mean , then the that came in, was probably bigger than it's own mean, and because co-variance is positive, this is what actually happens, we add something to . And the other way around works too, whenever is smaller than its mean, since covarince is positive, we are taking a little away from
if covariance of is negative, then an analogous argument can be made.
So we are making corrections on our prior, based on the covariance of the data and the prior.
The error of this linear estimator, increases when the prior itself is quite uncertain, that is, is large. And the error gets smaller when the correlation between and has a large magnitude.
Classical inference
Basically, here, we dont treat the input as a random variable. Rather, we might think about the input as a collection of parameters, that models our noisy measurements .
That is, we have different models or distributions on our measurement , and all of these together are parametrized by values of .
So how do we get a good estimator then? We use maximum likelihood. That is, for an estimation problem, in the classical setting, we simply want to pick . if we make a single measurement, we want to pick the parameters that make this measurement most probable. if we make a vector of measurements, (x is a vector) then we want the parameters that make this vector of measurements as highly probably as we can.
Compare this with beysian map inference, . using bayes rule, . Now, the denominator doesn't contain theta, and moreover, if we assume an "uninformative prior" where every is equally likely, then is a constant, so under these conditions, . Since the distribution on is uniform, there must be some probability model parametrized by giving probabilities that . Why is it so? well because the distribution of is already fixed, and decided to be uniform, so two different are equally likely. so we can say that each specifies a probability distribution on , that has nothing to do with how likely is, because all of them are equally likely.
Hence, in the case of an uninformative (uniform) prior distribution, Map inference and MLE (maximum likelihood estimation) are equivalent.
So we can write . in particular, if models a vector of independent observations, ( a joint distribution of ) Then,
Let us say we want to find the derivative of , wrt to then due to the chain rule of multiplication, we need to take the derivative of , and multiply with with all other terms in the product: do this for each , and add them all up. So we are doing about multiplications and additions.
since is strictly decreasing, equivalently, instead of maximzing we can minimize , whose derivative wrt to is much easier to calculate. Thati is, $$ \theta_{ML} = \arg \min {\theta} \sum^n -\log(p_{X_{i}}(x_{i}|\theta))$$
And $$\frac{dQ}{d\theta} = \sum_{i=1}^n \left(\left(\frac{{d}}{d\theta}{p_{X_{i}}(x_{i}|\theta)}\right) \cdot \frac{1}{p_{X_{i}}(x_{i}|\theta)}\right)$$ where only requires a linear number of terms.
The negative log probabilities, are also tied to information theory. Where the entropy of the random variable, is the expectation of the random variable obtained by taking negative log on the original one. .
So now an interested problem. Suppose we draw from a gaussian distribution with variance . what is the MLE of the mean?
So thats a gaussian. but if the variance is , then as well. so $$f(x) = ce^{-{(x-u)^2}/2}$$
So is the random variable resenting the joint, independent variables , each has the same gaussian on it as a distribution. so we want to calculate the probability of getting
so $$p_X(x|\mu) = \prod_{i=1}^np_{X_{i}}(x_{i}) = c^n\prod_{i=1}^ne^{-{(x_{i}-\mu)^2/2}}$$
Hence it is sufficient to maximize $$T(\mu) = \prod_{i=1}^ne^{-(x_{i}-\mu)^2/2}$$
Equivalently we can minimize (by taking -log on both sides) $$ Q(\mu) = \sum_{i=1}^n(x_{i}-\mu)^2 = \sum_{i=1}^nx_{i}^2 +n\mu^2 - 2\mu\sum_{i=1}^nx_{i}$$ Doing some calculus, and moving things around, we find the obvious $$ \mu_{ML} = \frac{\sum_{i=1}^nx_{i}}{n}$$
We can say that this is actually a random variable that depends on the random variables (which in our case is the same random variable sampled over and over).
So this is a random variable that depicts the estimator of the true mean . What is the expected value of this random variable? That is on average, when we do this sampling process many times and get many different 's, what would be the average we see?
well since in this case, each has the same gaussian distribution with mean , it turns out that the average is actually the correct mean which we are trying to estimate.
In other words, the random variable MLE estimator of , is expected to be the true mean itself. This means that our estimator is unbiased. On average, it does not favour something larger or smaller than the unknown it's trying to estimate.
So then, We might consider an estimator that we get by applying MLE to some noisy measurement who distribution is parametrized by the unknown we want to estimate.
call this estimator random variable Where this estimator depends on the vector we independently sampled (each from which comes with a model of our noisy measurements) when the true input parameter was .
Then, it is nice if the following properties hold for all :
Unbiased : . Now this is sometimes hard to come by for MLE estimators in general, but there are some nice asymptotic properties, for example that as we increase (the number of measurements we make) The estimators become more and more unbiased.
Consistency. That is, under probability measure (which is also a probability metric), Our estimator converges to the true parameters.