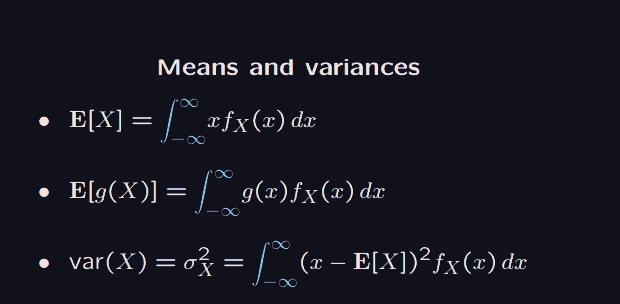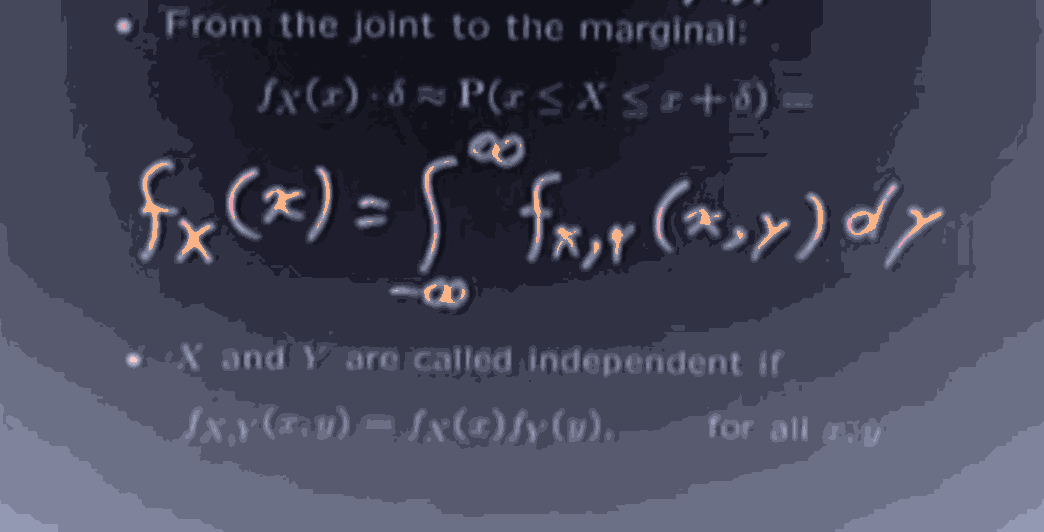We can use the same ideas, and do the syntactic analogies from sums to integrals.
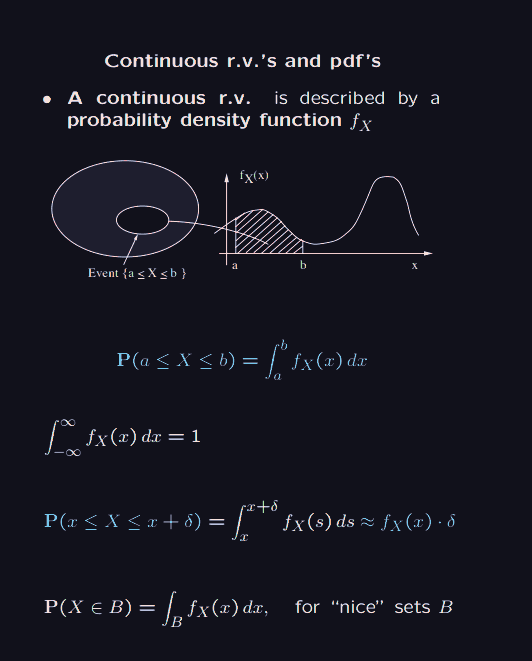
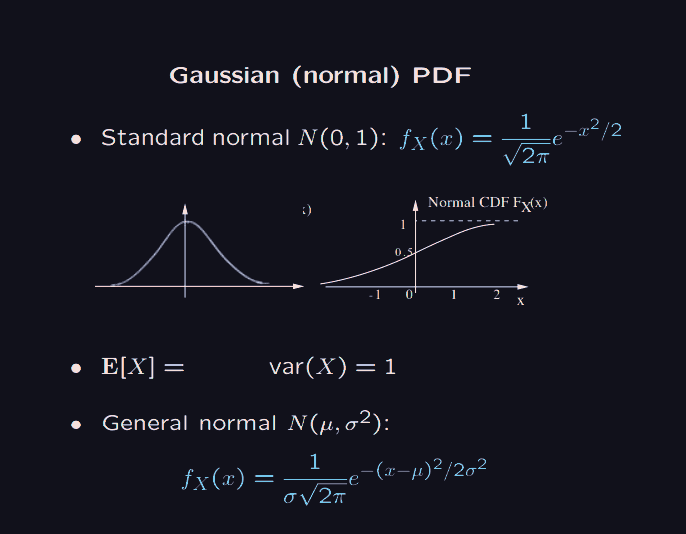
Here, the are called probability density functions.
We have for example the uniform distribution, which looks like .
In this case . Which is what we expect, if everything is uniform, we are likely to pick the middle value. and .
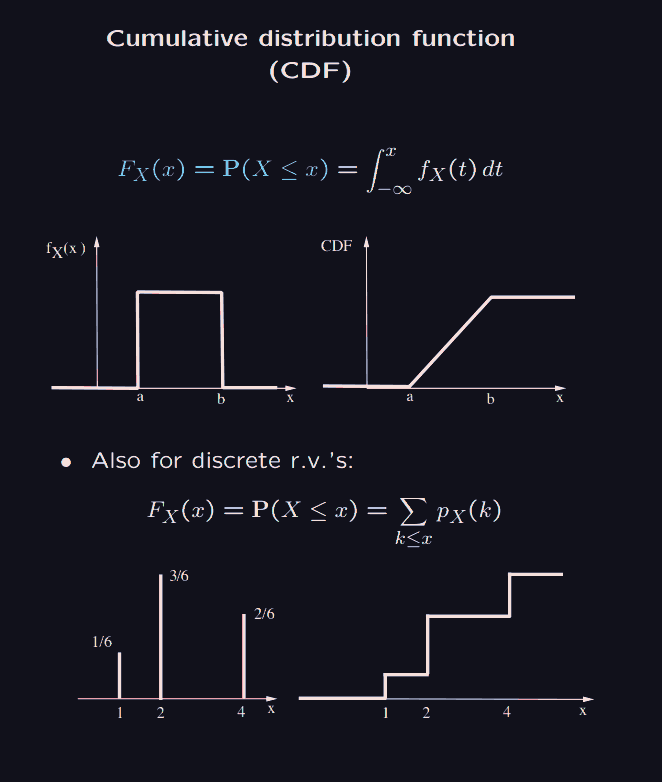
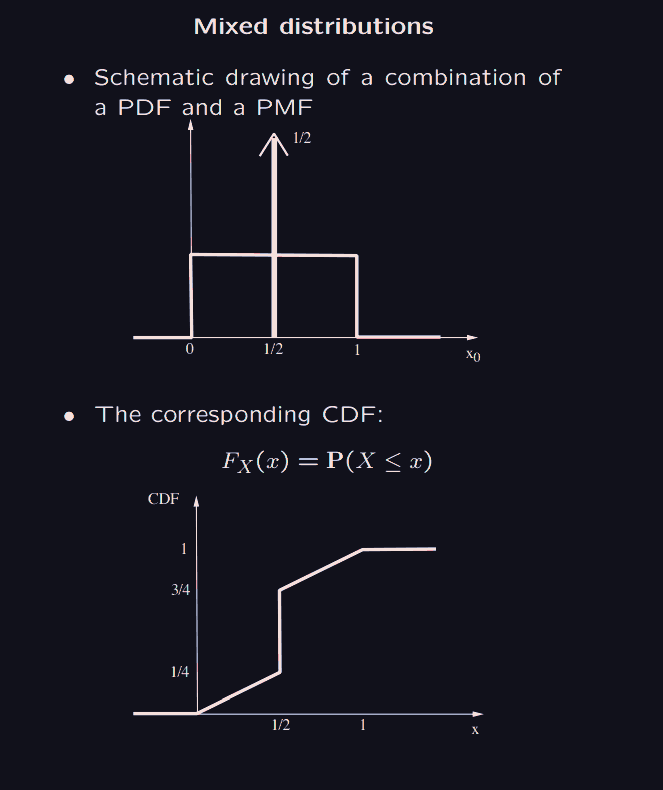
So the cumulative distribution function, at is the probability that the random variable outputs something at most . This is nice because they give some unified way of reasoning with both discrete and continuous random variables.
Let us dive deeper into bayes and conditioning.
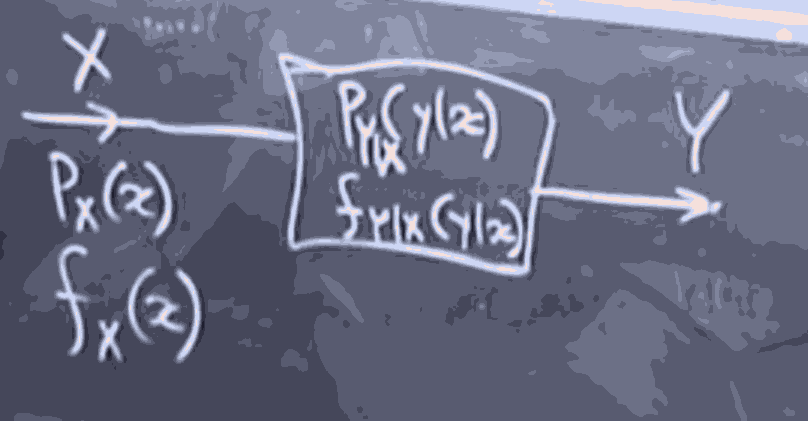
Suppose we have a random variable , and we know it's distribution when discrete (pmf) or when continuous (pdf). So the idea is that we know the DISTRIBUTION of , which goes through some blackbox that is kind noisy, and we get a random variable , the thing is, we can observe the values of only. Our model for the blackbox is the distribution , that is what is the probability (mass or density) of observing any given some
Now, what is the inference problem here?
Observing some collapses the real world into a state where we have observed this . Given this observation, what was the likely state of ? that is, we want to model the distribution .
having observed some , we want to know the probability that any went into the blackbox.
In another way, having observed , we want to make inferences about .
In particular, if we observe some and then some , then it is same as observing the pair , which is the same as observing some and then some .
allowing to denote either probability mass or density (depending on discrete/continous)
Hence (the bayes rule)
for example let us say is a signal, and we know its distribution (often called "prior"), and it goes through some noisy blackbox, which gives us an observable random variable , moreover, let us say we have a model of the noise .
From this information, we can calculate the marginal distribution .
And then using the bayes rule, we can infer the distribution .