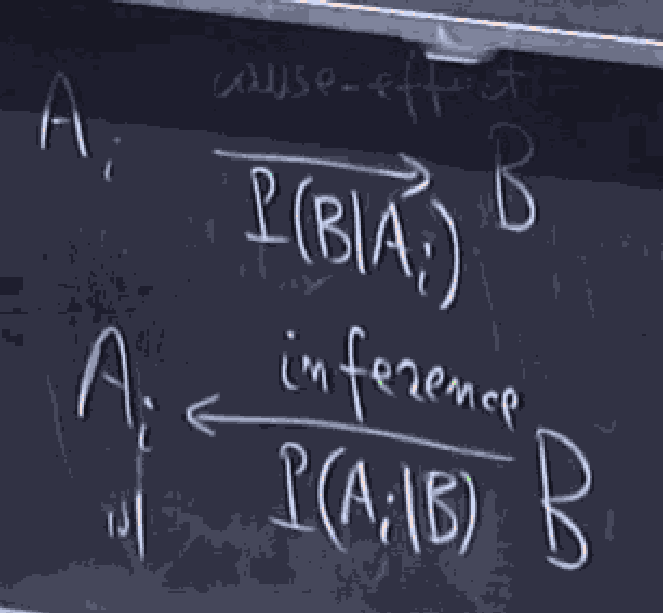The set of all possible outcomes of an experiment, such that exactly one of them occurs whenever we do the experiment, (mutually exclusive outcomes and exhaustive space of outcomes) like for example the outcome of a coin toss can't be both "H" and "T". Sample spaces are usually denoted .
Certain subsets of are called "measurable", and for all such subsets, we can assign a probability measure to them, so if is the collection of measurable subsets, then probability measure is a function . is called a sigma algebra on and is stable under countable union, compliment, and countable intersection, moreover .
There are three axioms on :
if , .
if is discrete and finite, the uniform probability measure of is .
if is continuous, then the uniform probability measure is the "area or nd-volume"
Note: Zero probability does not mean impossible. Points in continuous spaces have zero probability, yet the outcome of a certain experiment can be a single point. Similarly probability 1 does not mean the event occurs all the time. for example, the probability of getting any point on the uniform unit square, that isn't the origin is 1. (the origin has zero probability) yet ofc we can pick the origin.
conditional probability
If we get some partial information that event has occurred, Then the probability that event occurs given is : . This is essentially shifting the universe to . The axioms of probability measure still holds in this universe. for example, as long as are disjoint.
Suppose we partition into events . And is also an event. Then,
if we want to calculate , then we can write .
Hence, .
This is known as the baye's rule.
An alternative statement with , is .
If the occurrence of event produces no information about the occurrence of event (and vice versa), these events are independent.
In a conditional universe, if given the occurence of , the occurence of produces no information about the accurence of , then (this is called conditional independence).
If we had a game, where is some set of events, and is the payoff of each event. with the payoff of dollars occurring with probability . What is the expected payoff of this game?
If we play this game times, we are paid, dollars roughly times, for each payout . As gets very large, for each to , we are paid amount about times. so in games, if is very large, our total payout is , so averaging it out, the expected value .
Now, imagine that whenever event occurs, instead of getting a payout of , we get a payout of This is completely fine! To calculate the expectation of the new random variable , we know that whenever , the payout is instead .
Hence Allowing , we have the following picture
The variance tells you, what is the expected distance of a random variable form it's mean/expected value?, The standard deviation is the square root of the variance.
The conditional expectation of a random variable given an event , the sorta the average value we measure of , given event has already occurred. again, if has already occurred, then the probability that we get a payout of is equal to , where is the new probability mass from to where .
Hence .
Imagine partitioning the sample space into .
for any being the output of the random variable ,
we have that
This is because in a mutually exclusive manner, either event occurs, and we enter the context where the probability mass of is conditioned on , or occurs, entering the probability mass of conditioned on . Hence, we can write that
In general, $$E(X) = \sum_{i=1}^np(A_{i})E[X|A_{i}]$$ where is a partition of the sample space.
let be a random variable indicating the number of independent coin tosses after which we see the first "Heads".
Here the space of events is any sequence of coin flips, for any .
Now, we can partition this space into two events.
let be the set of all events where the first flip was a tail. and be the set of all events where the first flip was a head.
Then
But is the set of all events where the first flip is "Heads", therefore, . But is the set of all events where we flip a tail on the first flip. Since we have already flipped a tail, and subsequent coin tosses are independent, we have effectively come back to the same probability mass on , but we have spent one extra flip. Hence , using linearity of expectation, we get . Hence .
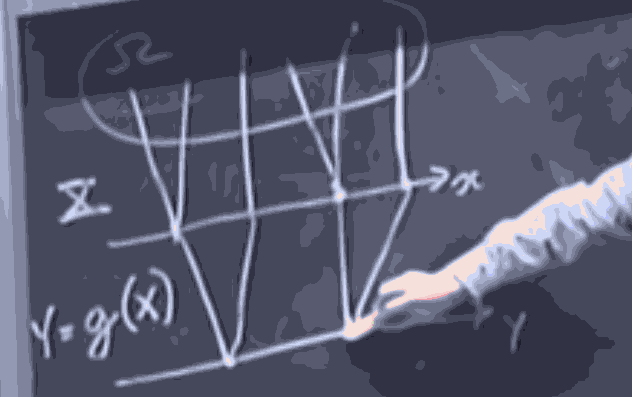
Joint distributions:
if are random variables, with mass functions , the joint distribution . We still have that
To extract the probability mass , we have . This is called the marginal distribution of , where we are marginalizing out .
Now, the joint conditional distribution . Here, we imagine fixing an output of the random variable as and for each such fixture, has the same "shape" as the "slice" of the joint distribution at that particular , but is re-scaled by the marginal of at that , to ensure that the probabilities add up to 1.
Just generalizing, suppose is a list of random variables, which take on tuple values for .
using our intuition, if takes values
Then first takes value , then conditioned to that, takes value , then conditioned to both of those, takes value and so on.
Hence $$p_{X_{1},X_{2},\dots X_{n}}(x_{1},x_{2},\dots x_{n}) = \prod_{i=1}^n p_{X_{i}|X_{1}, X_{2}, \dots X_{i-1}}(x_{i}|x_{1},x_{2},\dots x_{i-1})$$
Where the variable is condition on all the previous ones.
Now, if it is true that these random variables are pairwise, triple-wise and so on independent, that is the occurrence of any sub-set of these random variables taking some value, gives no information about any other random variable, then for any sub-set indexer
So if random variables are independent, then using the conditional expression seen above, with the other expression even more above, we get:
That is, if the random variables are independent, their joint probability mass is the product of each marginal probability mass.
If are random variables, with the tuple giving payout, then the expected value: $$E[g(X_{1},X_{2},\dots,X_{n})] = \sum_{x_{1}\in X_{1}} \sum_{x_{2} \in X_{2}} \dots \sum {x \in X_{n}} g(x_{1},x_{2},\dots x_{n}) p_{X_{1},X_{2},\dots X_{n}}(x_{1},x_{2},\dots, x_{n}) $$
Here again, we can show linearity, let be the map Just using our eyes and mind and the distributive law, and factoring things out, we have:
So the expectation of a linear combination of random variables, is the linear combination of the expectation of random variables :)
now if is the product function , moreover if the random variables are independent, then:
in the innermost product, the first terms are independent of the last summation which sums over only possible values of the random variable hence, we can factor them out:
equivalently
Continuing this process, we get
Notice that for variance, Solving, we get
Now, if are independent, Therefore,
Indeed by induction if for are all independent of each other, .
Binomial distribution, is the random variable X, which counts the number of successful trails of independent trials, where the probability of success is , and failure is . We can use the indicator variable trick.
The good thing about expected value is that it doesn't care about independence.
in the above problem, the are not independent. if I tell you that each from are all 1, that means that the last remaining hat is the hat of the person, so it does change the probability of the nth guy finding his hat, from 1/n given no information to 1 giving this peice of information.