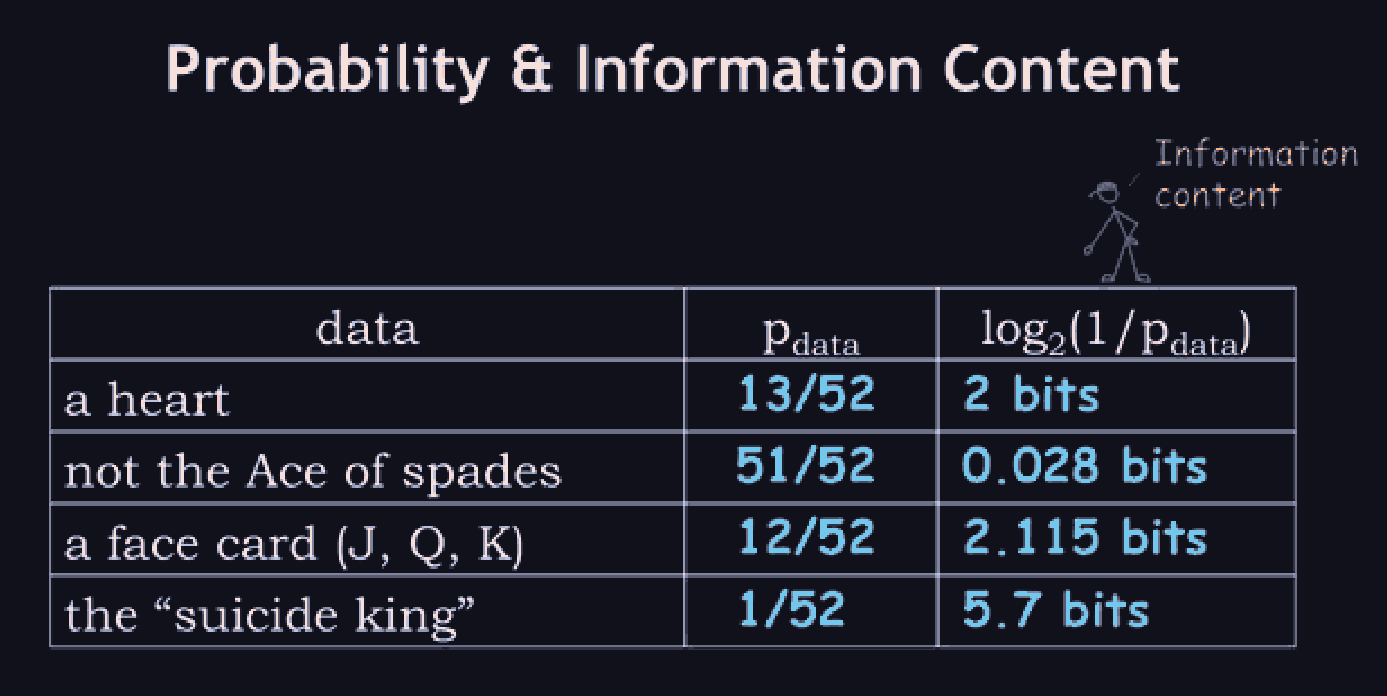
Data communicated or received that resolves some amount of uncertainty about a fact/circumstance.
For example, if we draw a card from a 52-card shuffled deck, the following are in increasing order of information : it's a red card, its a heart, its the two of hearts.
The "self information" of a value of a random variable is: $$ I(x) = -\log(p_{X}(x))$$ >The entropy of a random variable is the expected amount of information of that variable. Remember that for any deterministic function , and a random variable , is a random variable as well. Therefore, the entropy of a rv is defined as: $$ H(X) = E[I(X)] = \begin{cases}
-\int_{-\infty}^\infty f_{X}(x)\log(f_{X}(x))dx \ \ \ \ \ \ \ \text{continuous rv} \ \
-\sum_{x}p_{X}(x)\log(p_{X}(x))dx \ \ \ \ \ \ \ \ \ \ \text{discrete rv}
\end{cases}$$
If we have a sequence of data drawn from an rv , then (as the sequence gets long) if the average number of bits: used to transmit this data, is less than we haven't transmitted enough information, if its more, we're inefficiently transmitting too much information. For long sequences of data with underlying rv , its perfect to transmit an average of bits of information.
Encodings
The first one is a valid encoding, since these is an unambiguous way to decode, given the key, and its fixed length sinch each symbol in the set get a fixed number of bits as its encoding. The second one is also valid but is a variable length encoding. The third one is invalid because there is ambiguity in the decoding given the key.
In order to ensure an unambiguous encoding, we can tree it and check if each symbol is a leaf. Then there is as unique path from the root to each symbol, where we can unambigously [[]]decode.
Fixed length encoding gives us random access decoding, if we want to decode from the 'th letter in the decoded message, and we have symbols, we need to skip roughly bits and start decoding from there. Otherwise if each symbol has bits assigned to it in the encoding, we skip bits and start from there instead.
Notice that (-1) in the two's compliment is just a string of all 1's, so subtracting A from it is just flipping each bit of A.
Therefore in 2's compliment, where is the bitwise compliment of .
The rough idea is that for a symbol assign as many bits as .
Let be a set of symbols, and a probability on each symbol.
The entropy of the set of symbols .
let depict the the number of bits each symbol is mapped to under a valid encoding.
The expected length of the encoding of a symbol under this, given .
For symbols, the lower bound on the expected encoding length is , and the expected encoding length of a particular encoding is .
Huffman's Algorithm:
Let and a probability on each symbol. We construct an encoding tree as follows:
informally:
take two symbols/subtrees with the lowest probability symbol/root probability, combine them to form a new subtree.