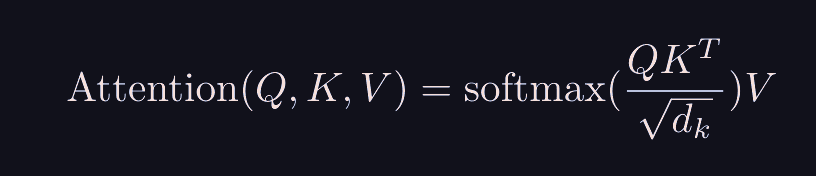note, we will adopt a row first approach as is the nature of pytorch, even though column vectors as features agree with linear algebra convention more.
Now, there is a lot of oversimplification as to how a transformer actually works. Let us start with a very simple idea.
let us say we have an input sequence and a target sequence .
During training(for autoregressive models): and we want to predict
Actually what happens is: we pass as a matrix to the "encoder block" and we right shift the target into the "decoder block".
So given we need to produce a .
And the loss is then against .
So to be very clear, in order to predict a 4 length sequence from a 3 length sequence, we need to pass the 3 length sequence into the "encoder block", Pass a right shifted target sequence (which is the same as the input sequence if its an autoregressive task, or its different for translation type stuff). And then using both, we predict the entire output sequence and evaluate it against the full target sequence (both of length 4).
So, let and both as matrix-one-hots.
then, we pass into the "encoder" and into the "decoder". In theory, the prediction is auto-regressive, in the sense that only is used to predict , (where in auto-regressive non translation type stuff).
and so on. In practise, are passed at once, and we use attention and masking to parallel emulate auto-regression.
we predict and then take .
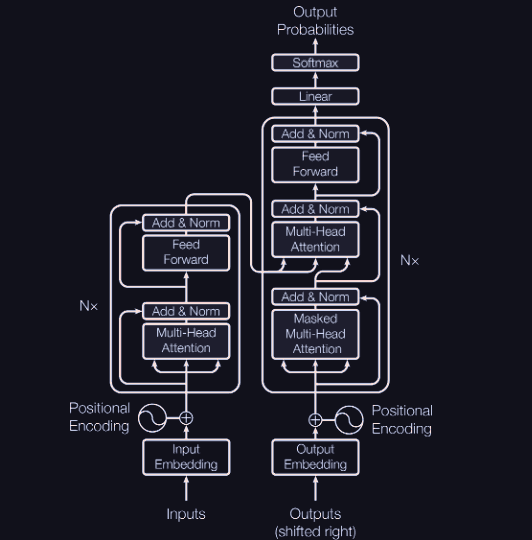
Let us see what's happening at a high level here:
first we embed the one hot vectors into some vector space.
Then we introduce some positional encoding . Then we feed it through encoder blocks notice that each encoder layer is different, and power is used to denote applying them sequentially because I like brevity.
So is the encoding. Now there are decoder blocks as well. And each decoder block recives in its forward pass! Moreover the first decoder block receives where and is as usual a positional encoding.
then , and loss is .
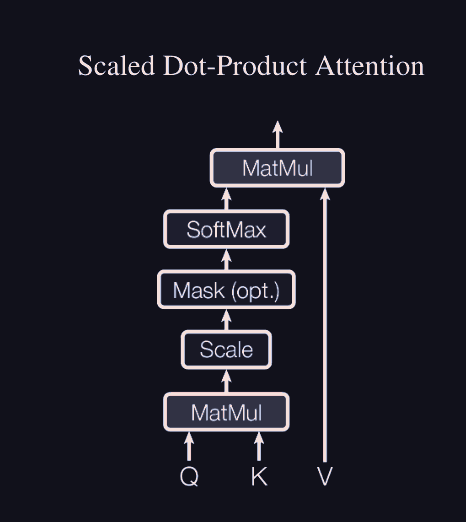
Self-Attention: Scaled-Dotproduct:
so, given an embedding matrix of shape we make three linear projections of this model: .
both or is the key/query dimension. and has shape
So we compute the dot product between the and matrices, and then scale it by the key dimension. we also optionally mask the upper-triangle with -inf to zero out the attention of future time-steps with current ones. and then finally matmul by .
it is pretty clear that the output of a single attention head has shape . as the has shape computing the attention pattern.
For multi head attention, we use the same embedding matrix and pass it through different heads. we choose to be so that after concatenating the outputs of multiple heads and matmul by we get a matrix of shape again. Once we understand attention, there is not much else to the architecture:
Encoder block:
does multi head attention and a residual connection adds the original embedding to the output of the multi head attention. Then we normalize, then pass through an MLP and then do another residual connection and normalize again
so applying multiple encoder layers in chain gives us the final encoding . For an encoder block which isn't the first one, we use the output of the previous encoder block in place of .
Decoder block:
once encoding is done, let be the position-ally encoded, embedded version of .
Then, for the first decoder block,
and for future decoder blocks, the previous block's output is used in place of and the encoded matrix is passed to EACH DECODER LAYER.
finally we apply multiple decoder layers and then a linear followed by softmax to get , and do grad descent on cross entropy between and .
A small caveat,in actuality,the encoder-decoder attention, the one that we wrote actually uses the final stored matrices from the final encoder head (from the output encoder head) and the comes from the previous decoder layer.
For all other attention heads, it uses its own as usual.
Why attention?
so here, (in self attention) per layer, we only do 1 sequential operation, the complexity per layer is fully parallelised. Moreover, the most important thing is that the number of forward props we need to do to process a full sequence is just one. (upto big O). In a recurrent model, if the seq length is we need to do forward props and then BPTT. but transformers process sequences in one batched go. so the forward prop path length is constant, independent of sequence length in a transformer.
Superposition:
In theory we would love for each semantic "idea" to be embedded into perpendicular dimensions. That is if d_model = N, then we can encode different semantic ideas as perpendicular directions, and represent a combination of ideas as component sums of each direction.
However, if one relaxes and allows an free perpendicular encoding of semantics, that is each semantic is at most angle away from being perpendicular to any other semantic, then the number of directions grows as !!!! So in this case, we have exponential growth in the number of possible directions for a "semantic feature", however this also means that most semantic features are not a single direction or a single neuron, which is one of the theories on why LLM interpret-ability is hard.
We will reserve implementation and training details to another time, this was just the core architecture.
Sources: 3b1b deep learning series, Attention is all you need paper, my brain.