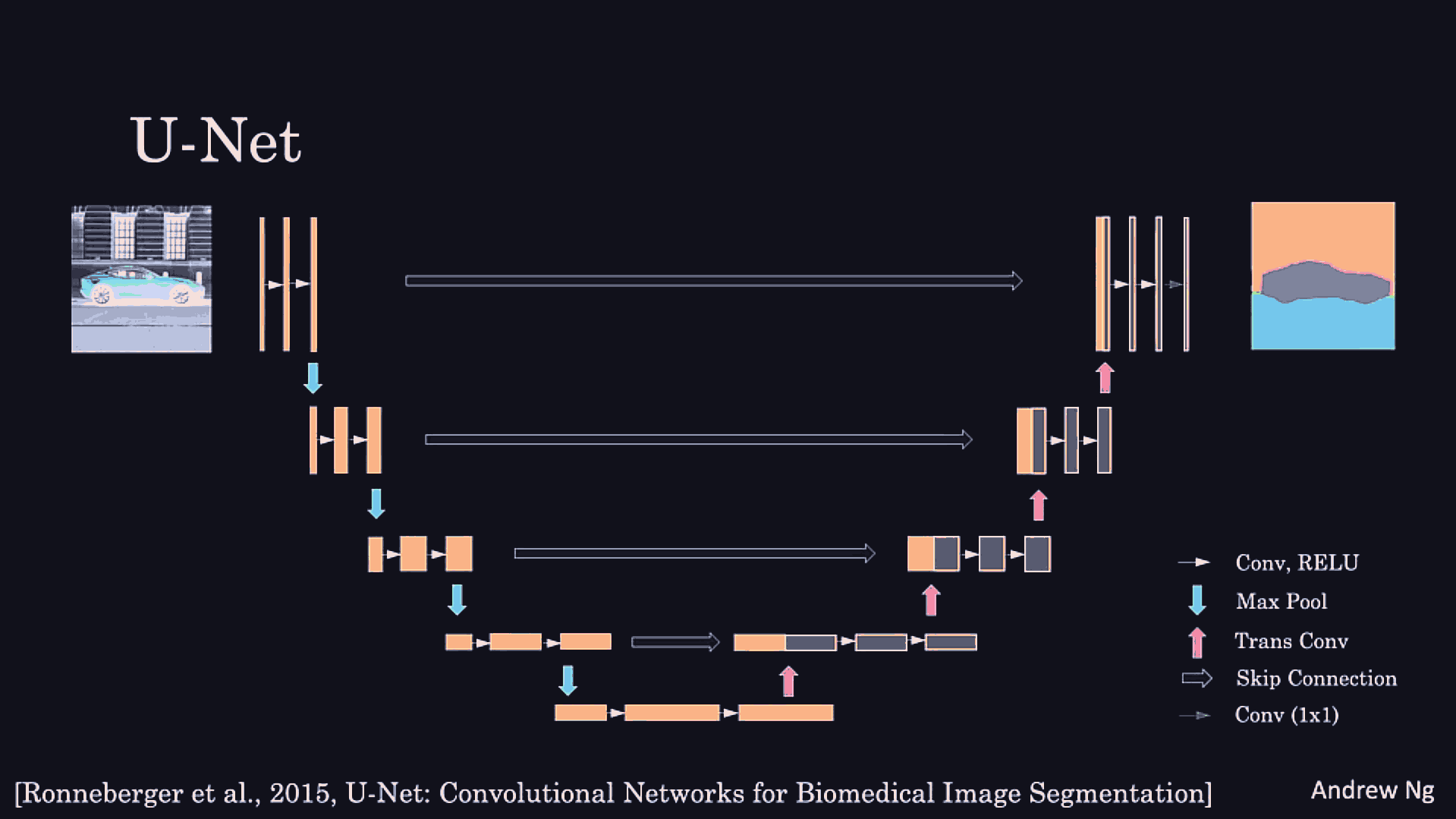
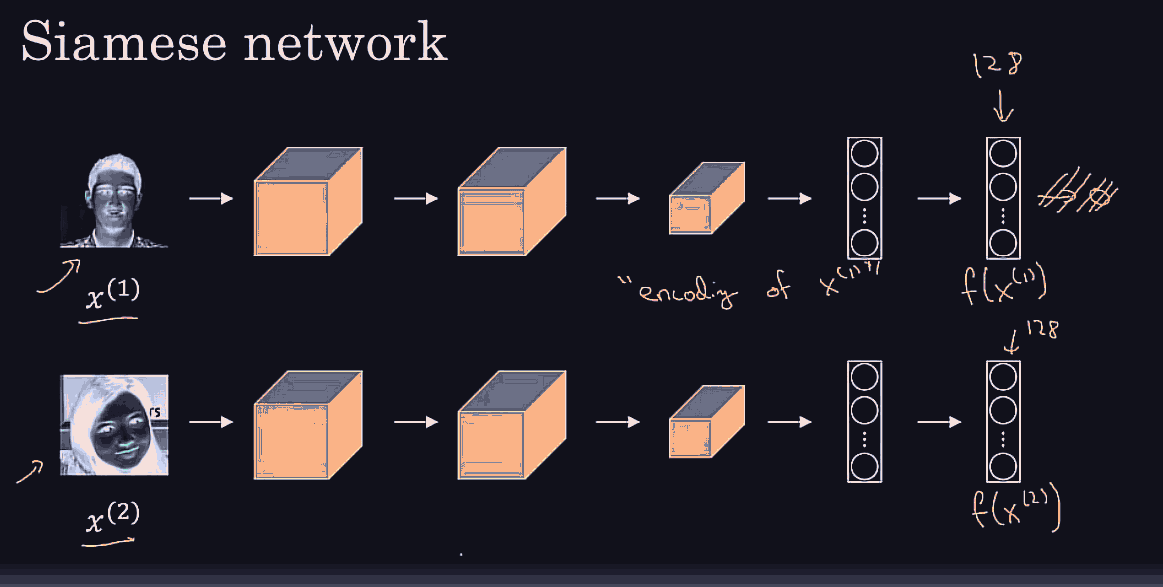
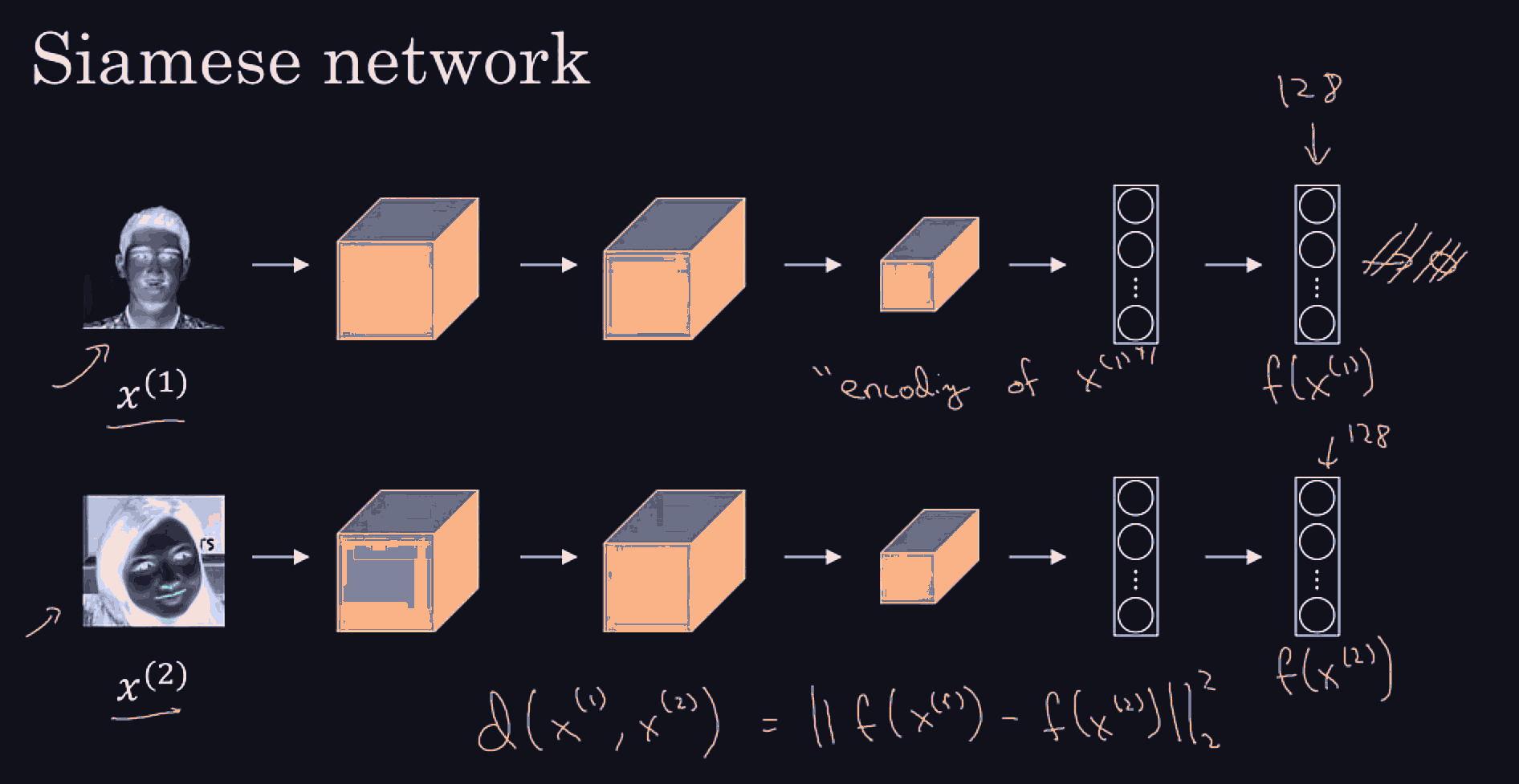
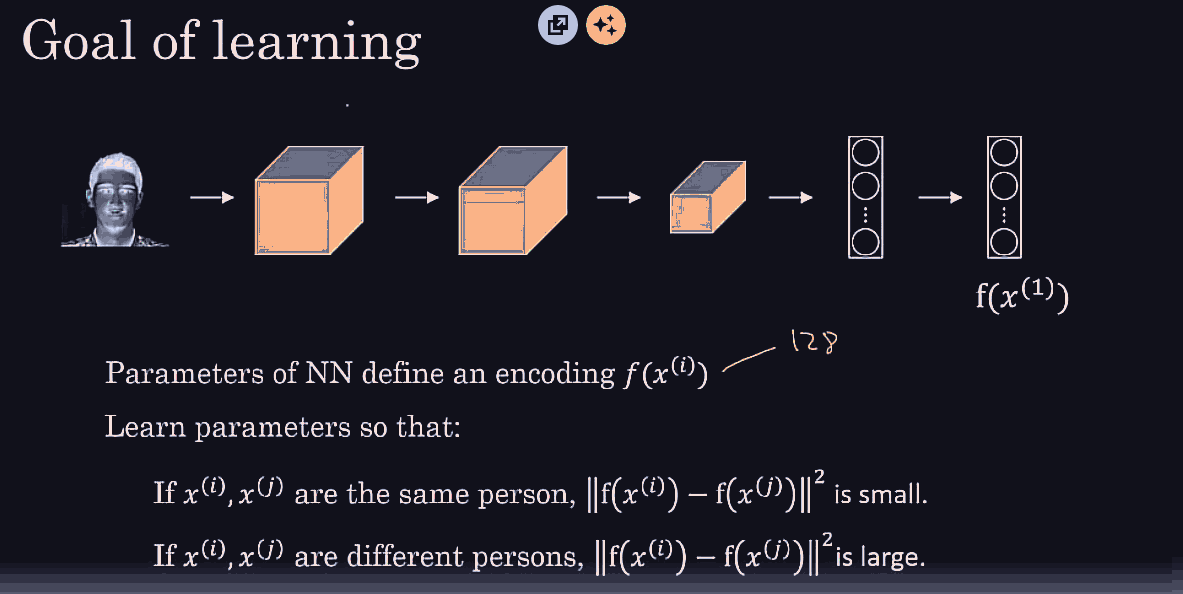
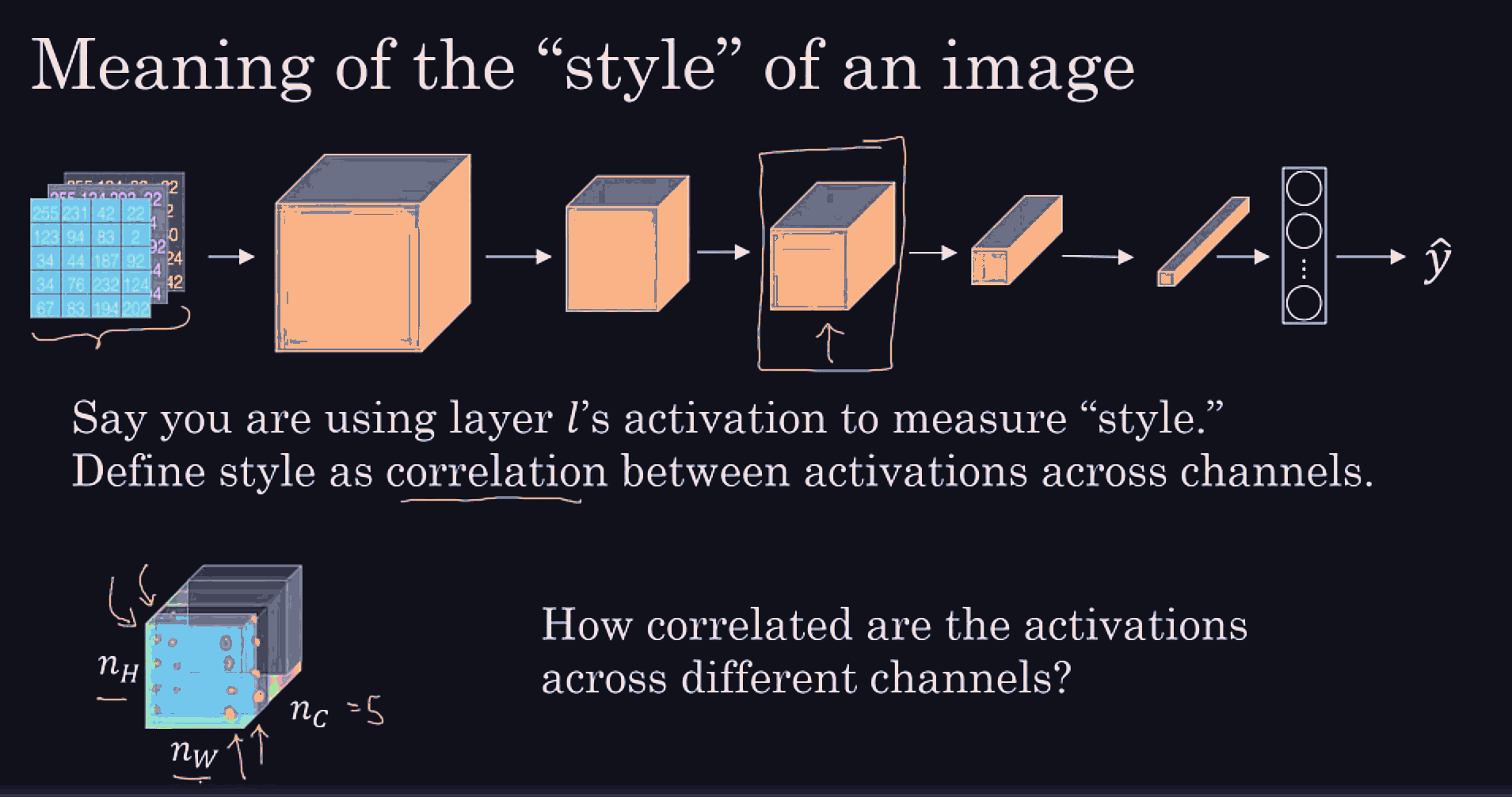
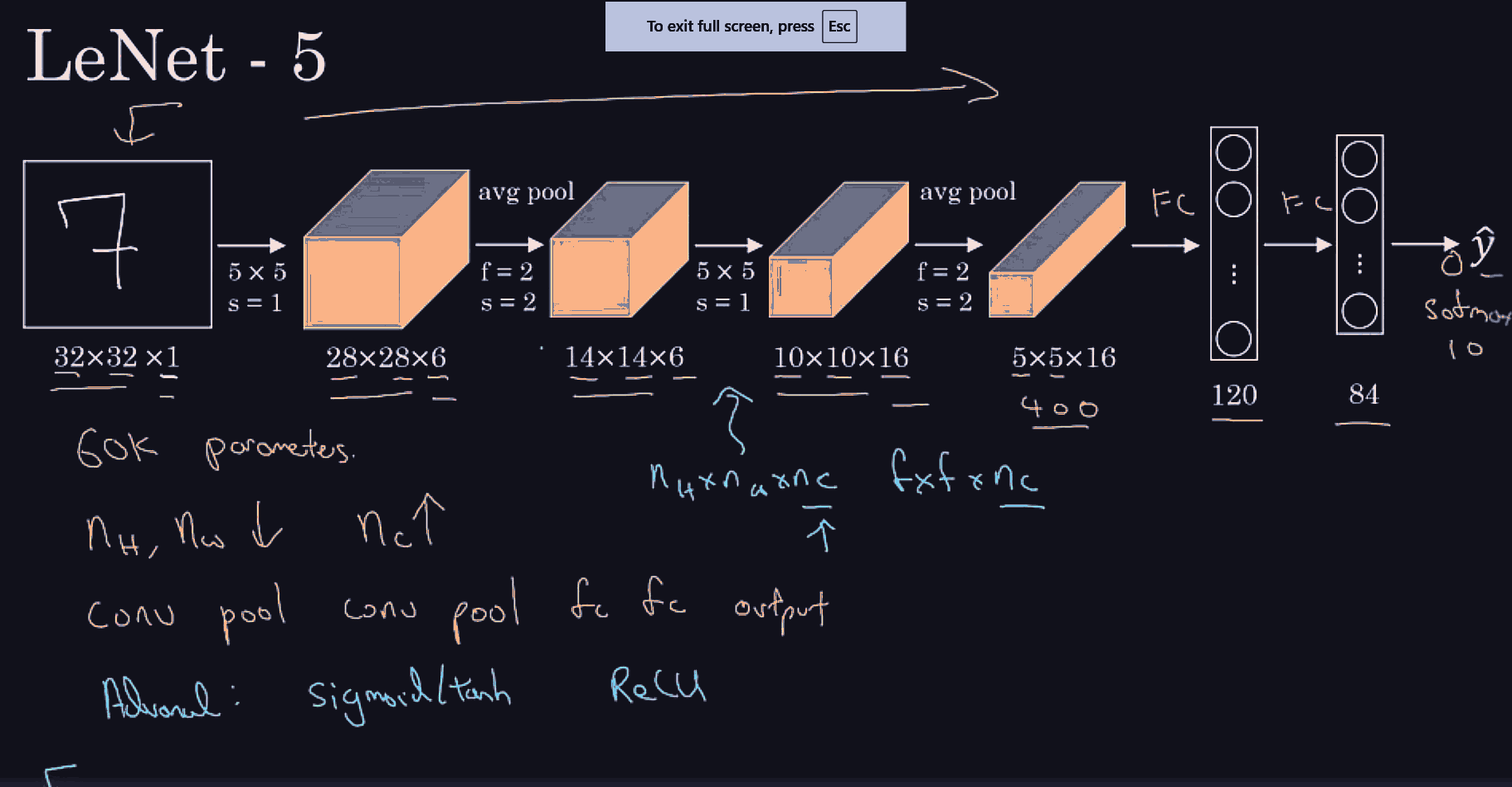
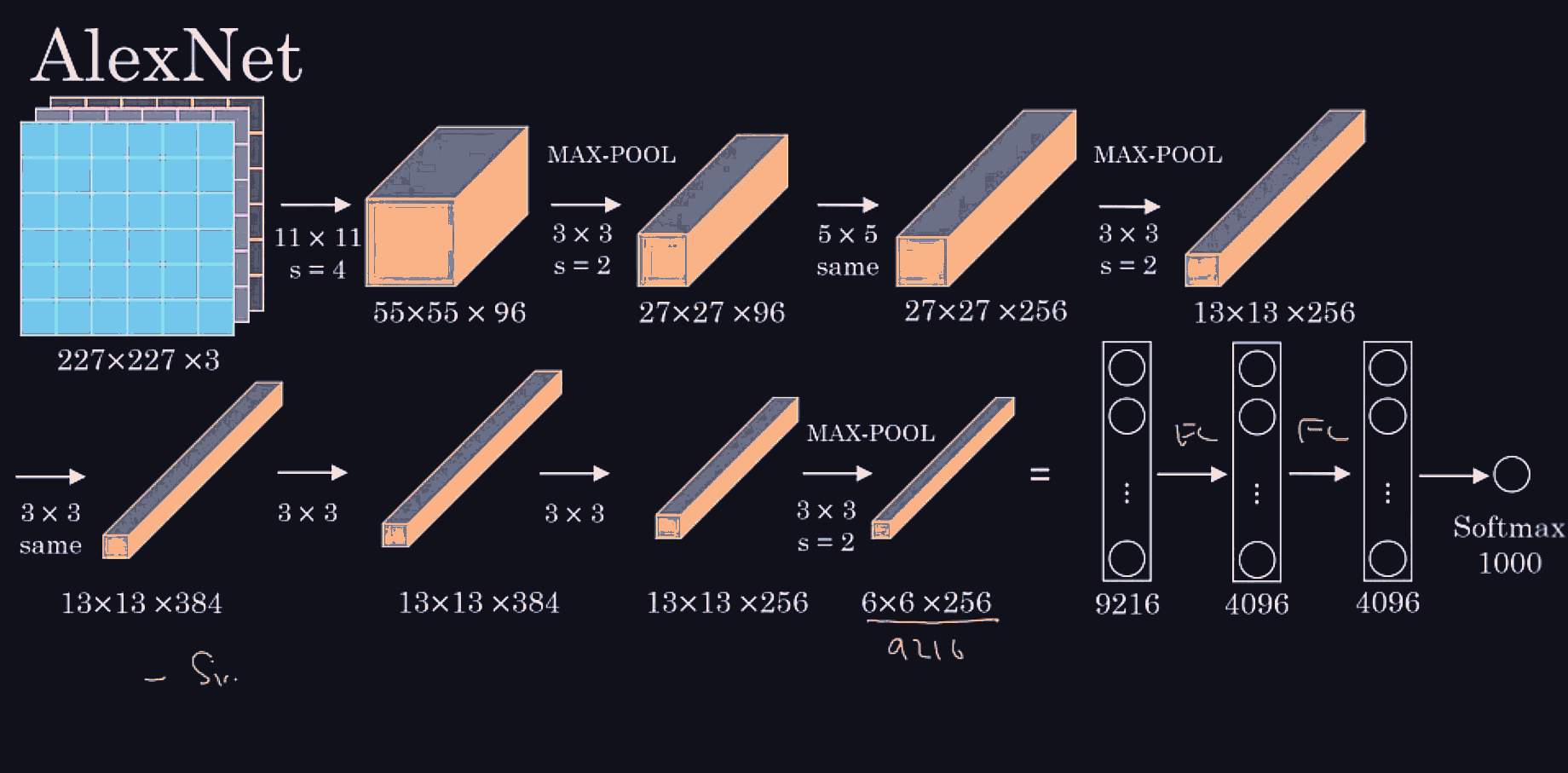
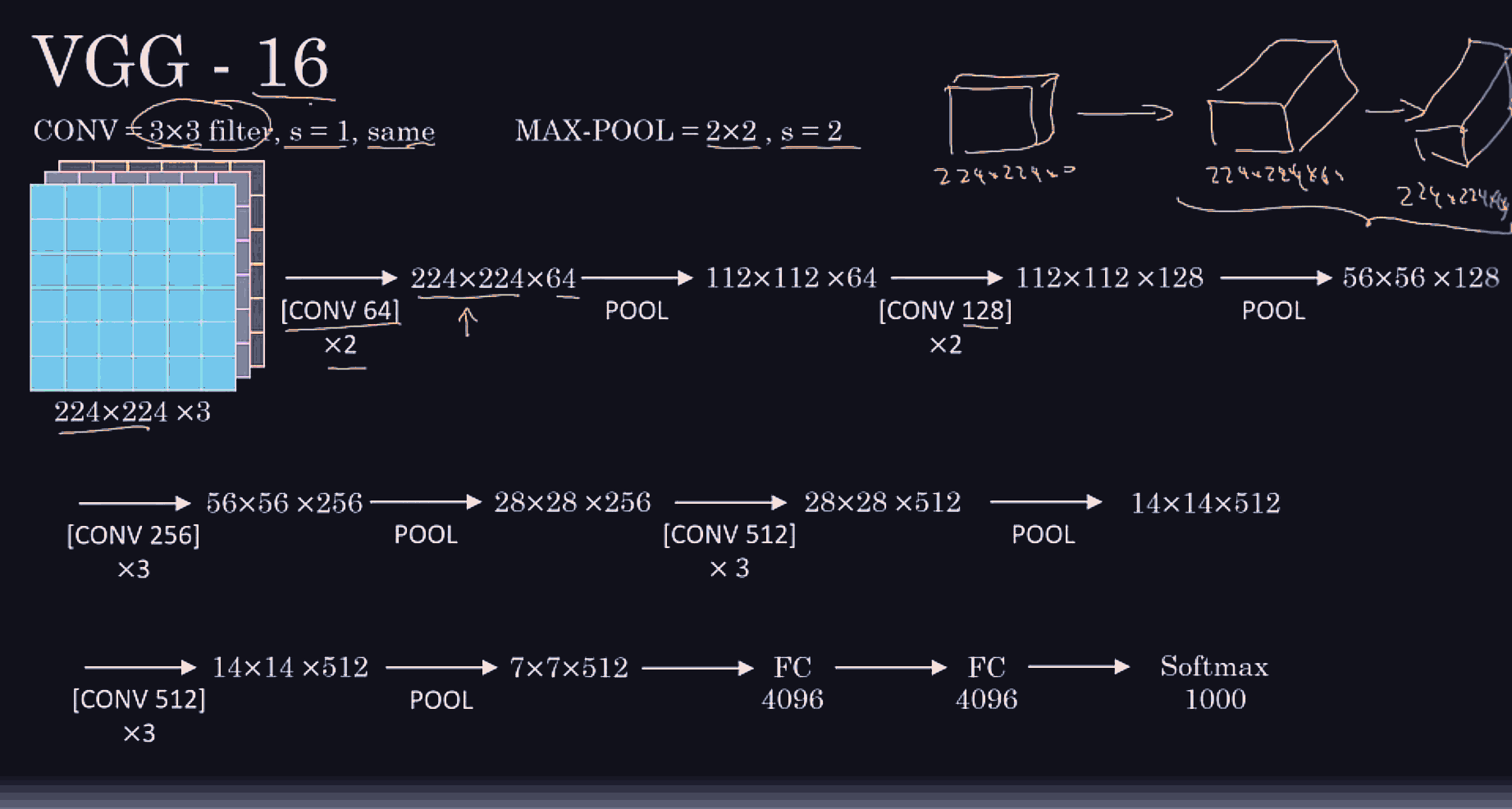
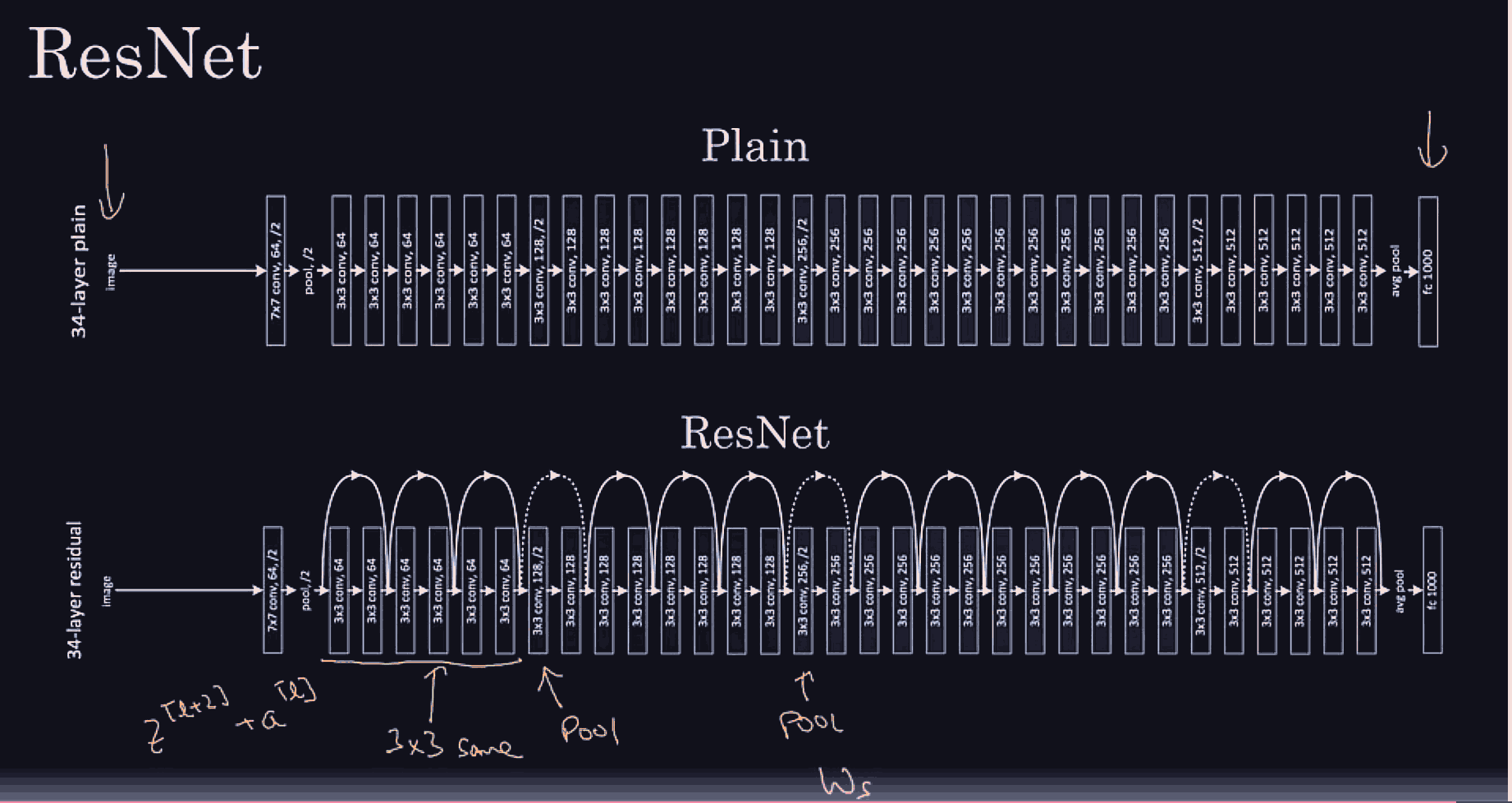
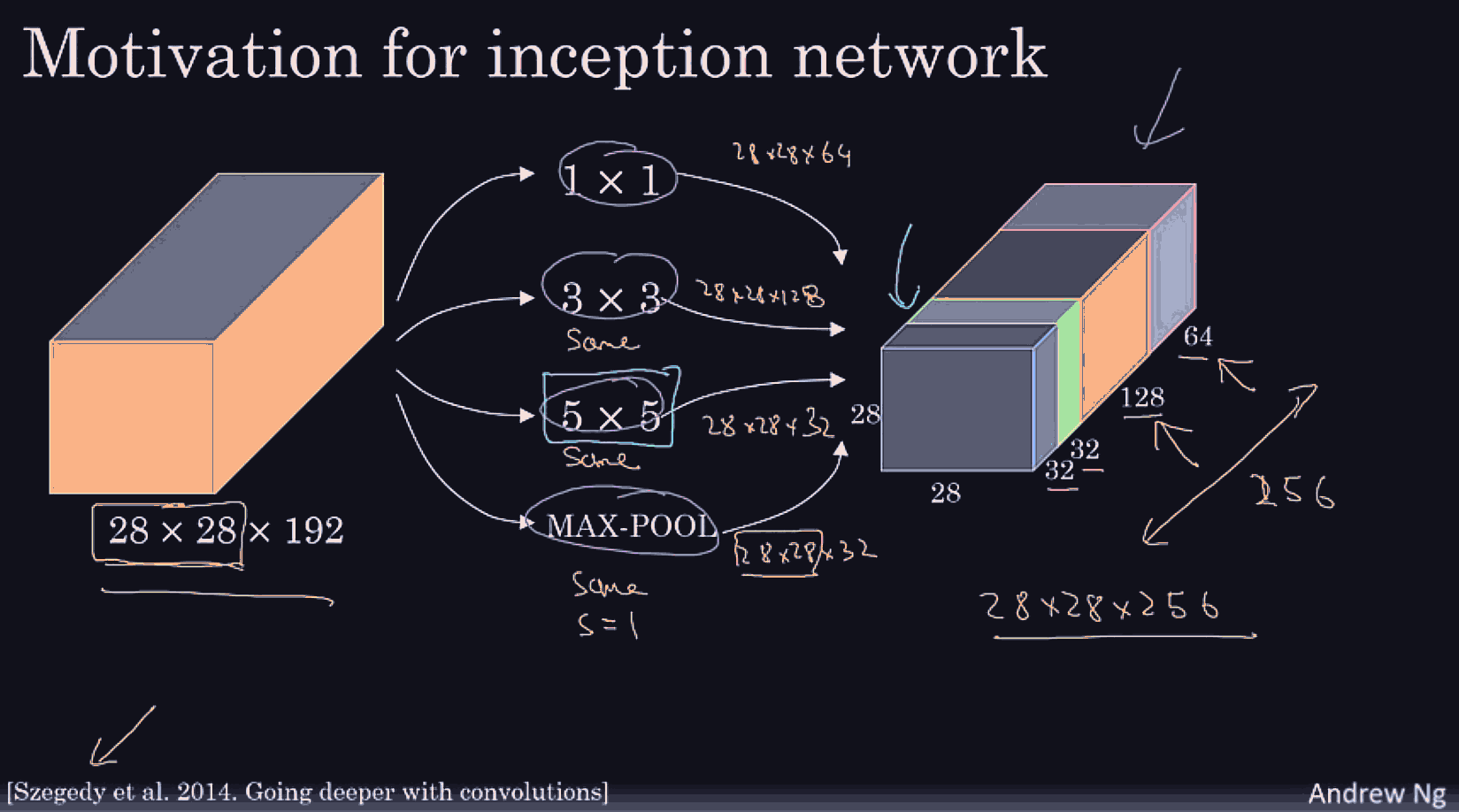
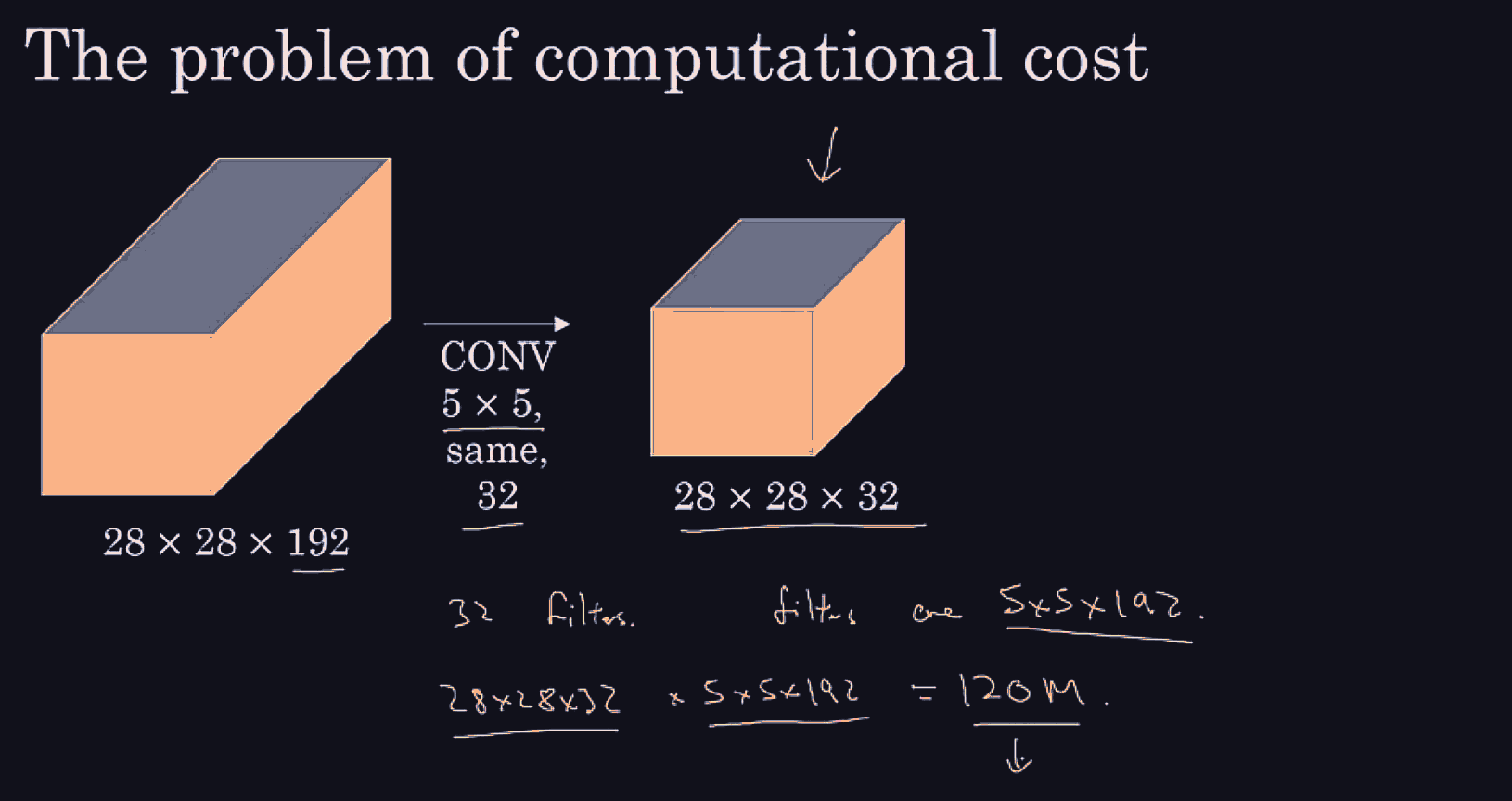
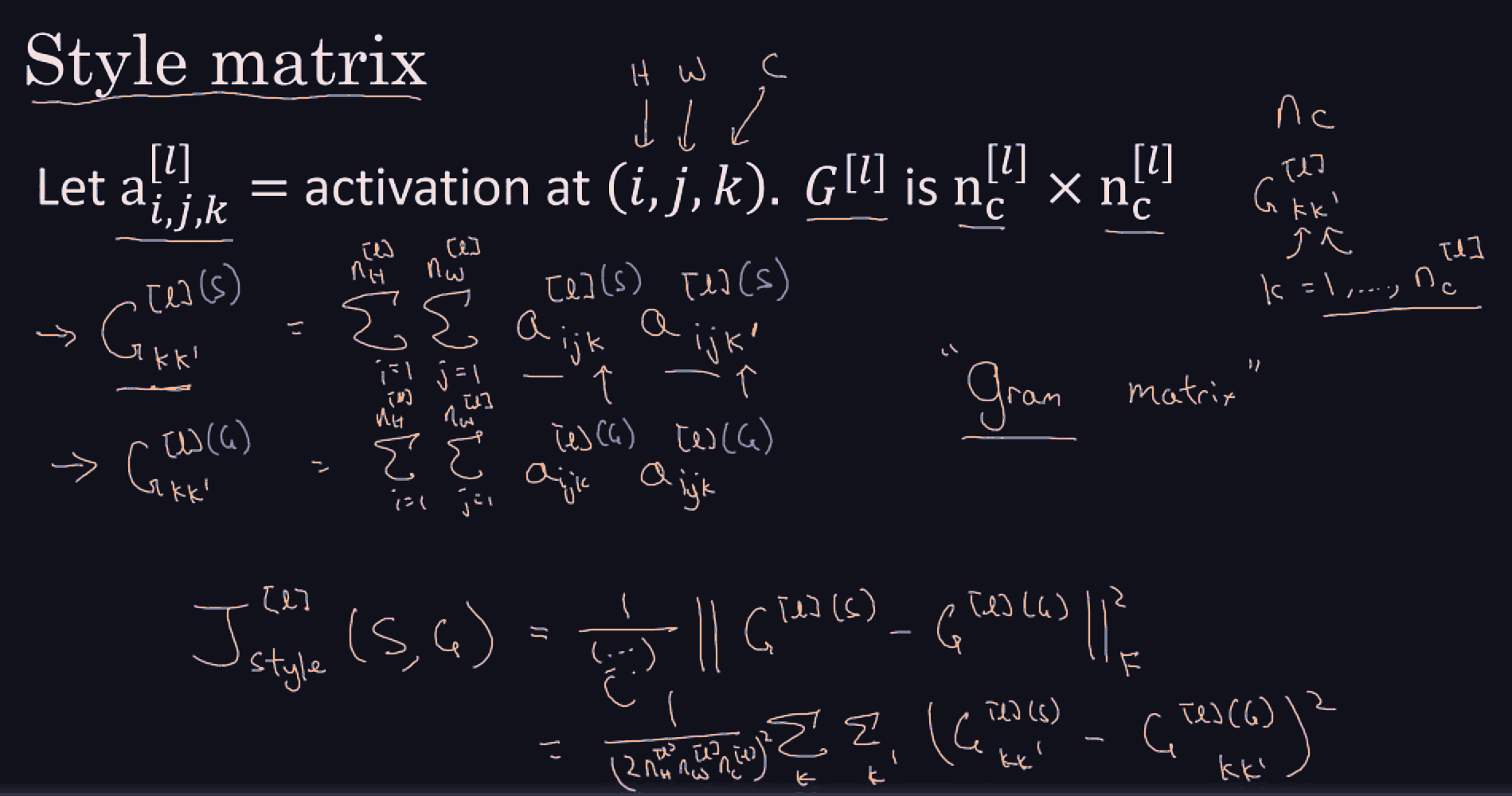Conv net architecture
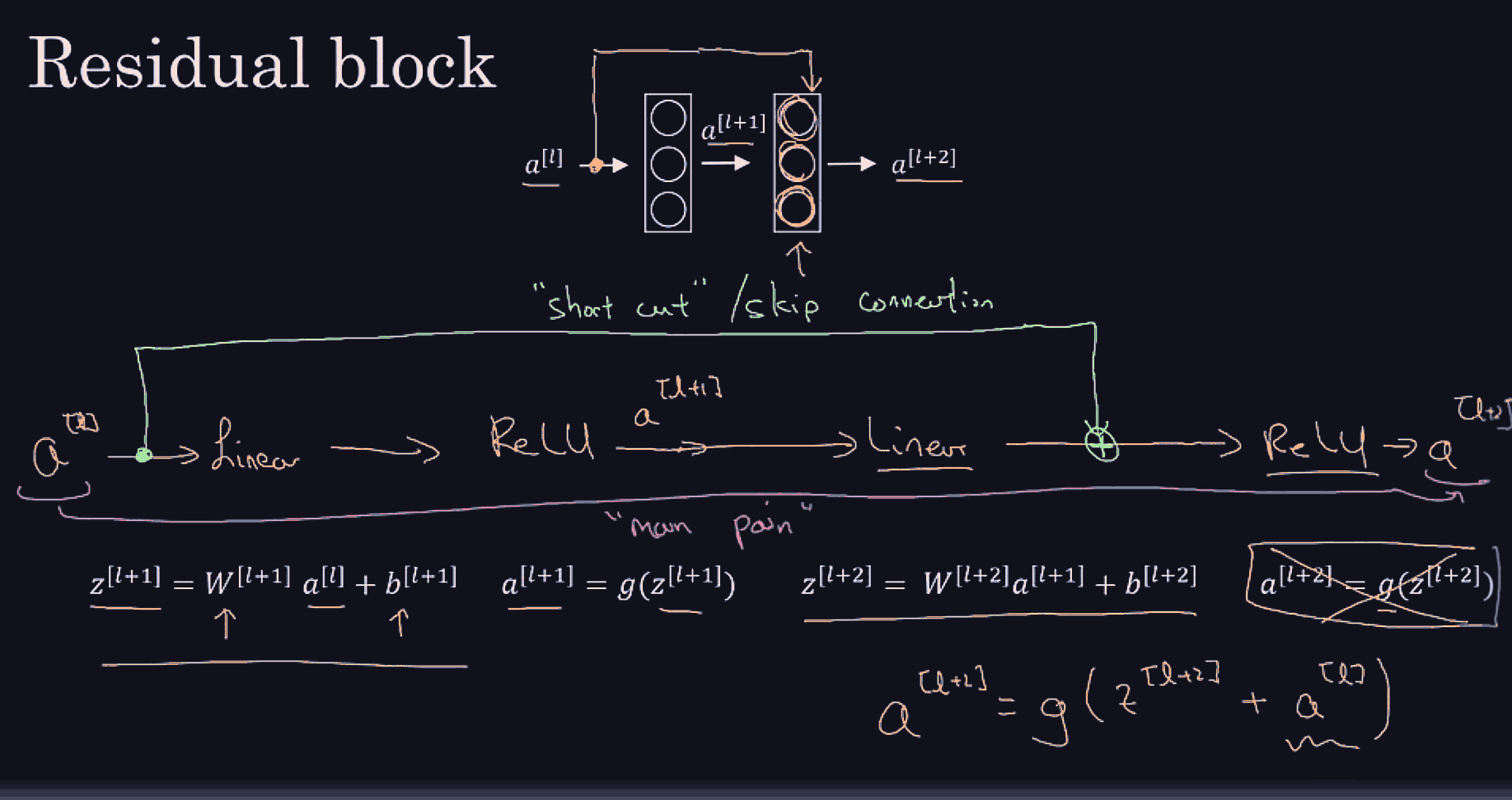
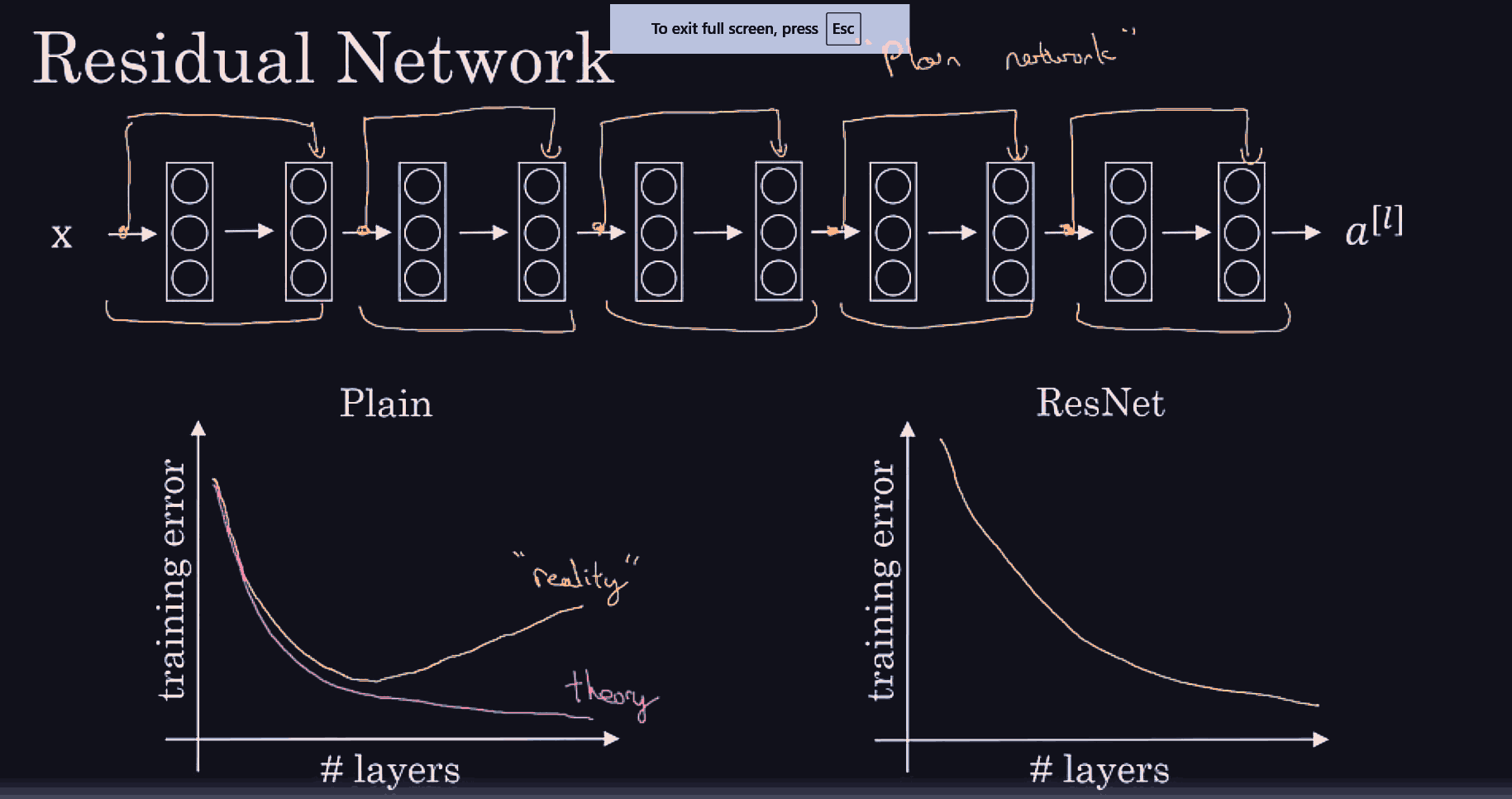
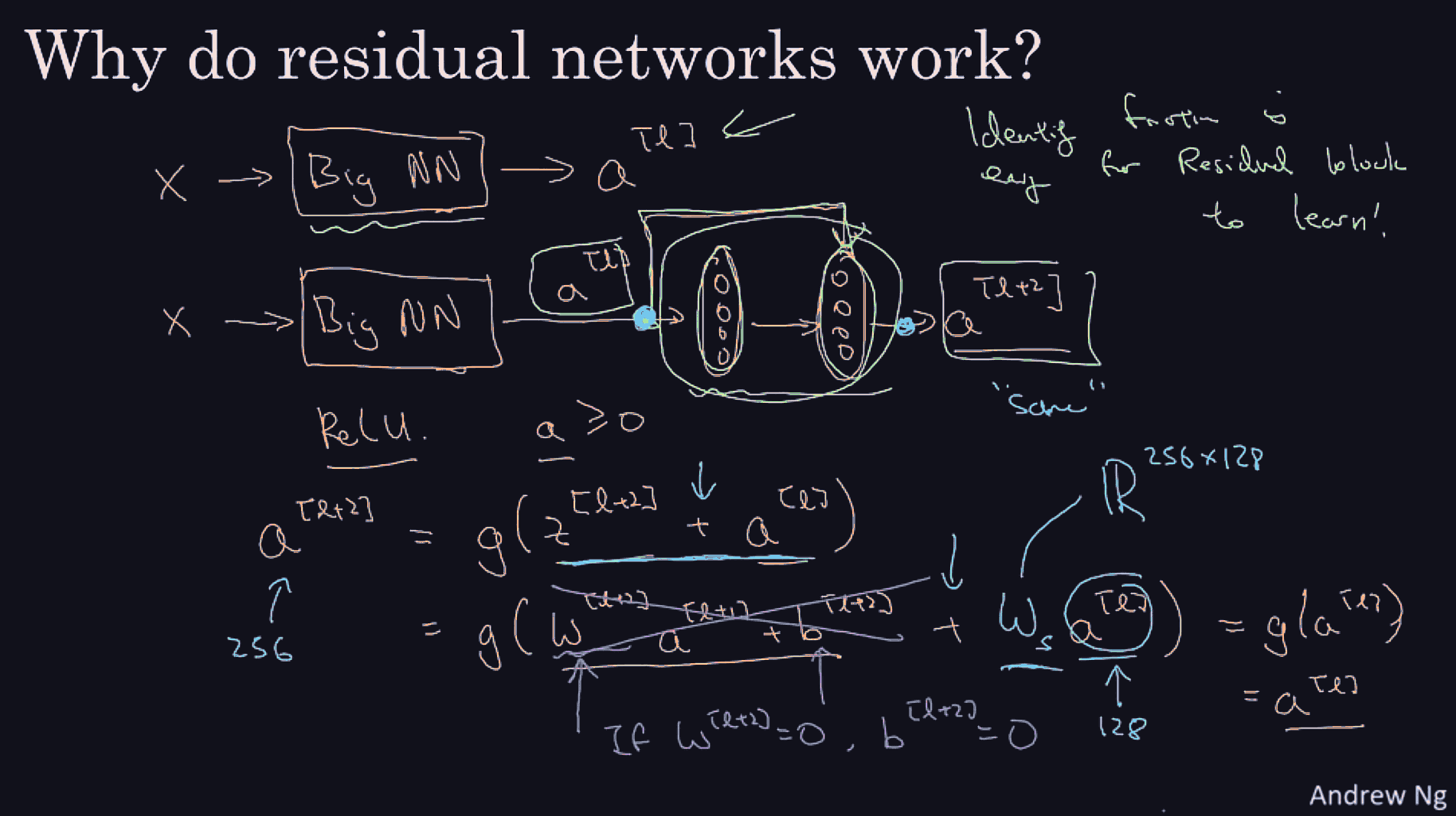
Basically, res nets allow an easy learning of the identity map from

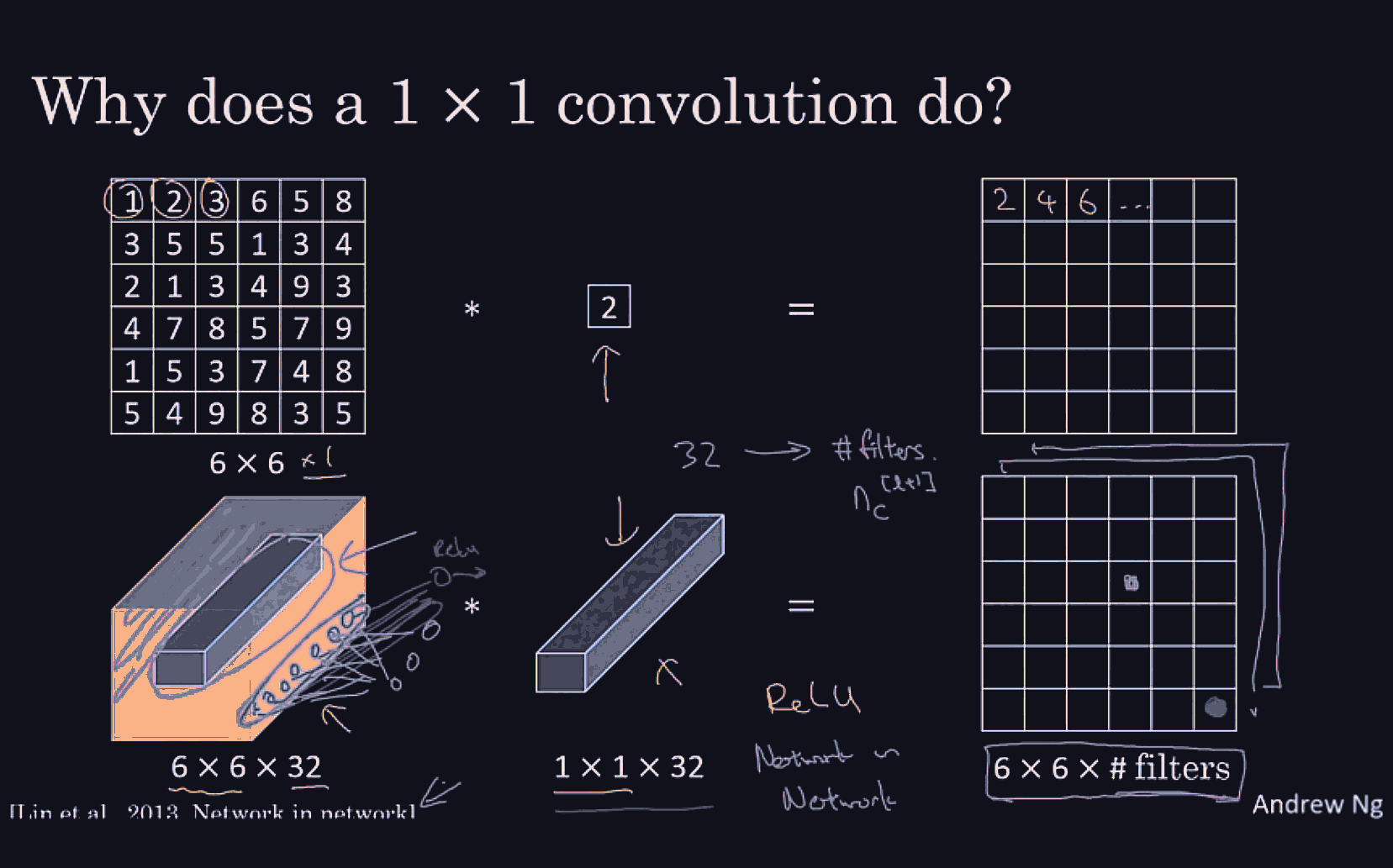






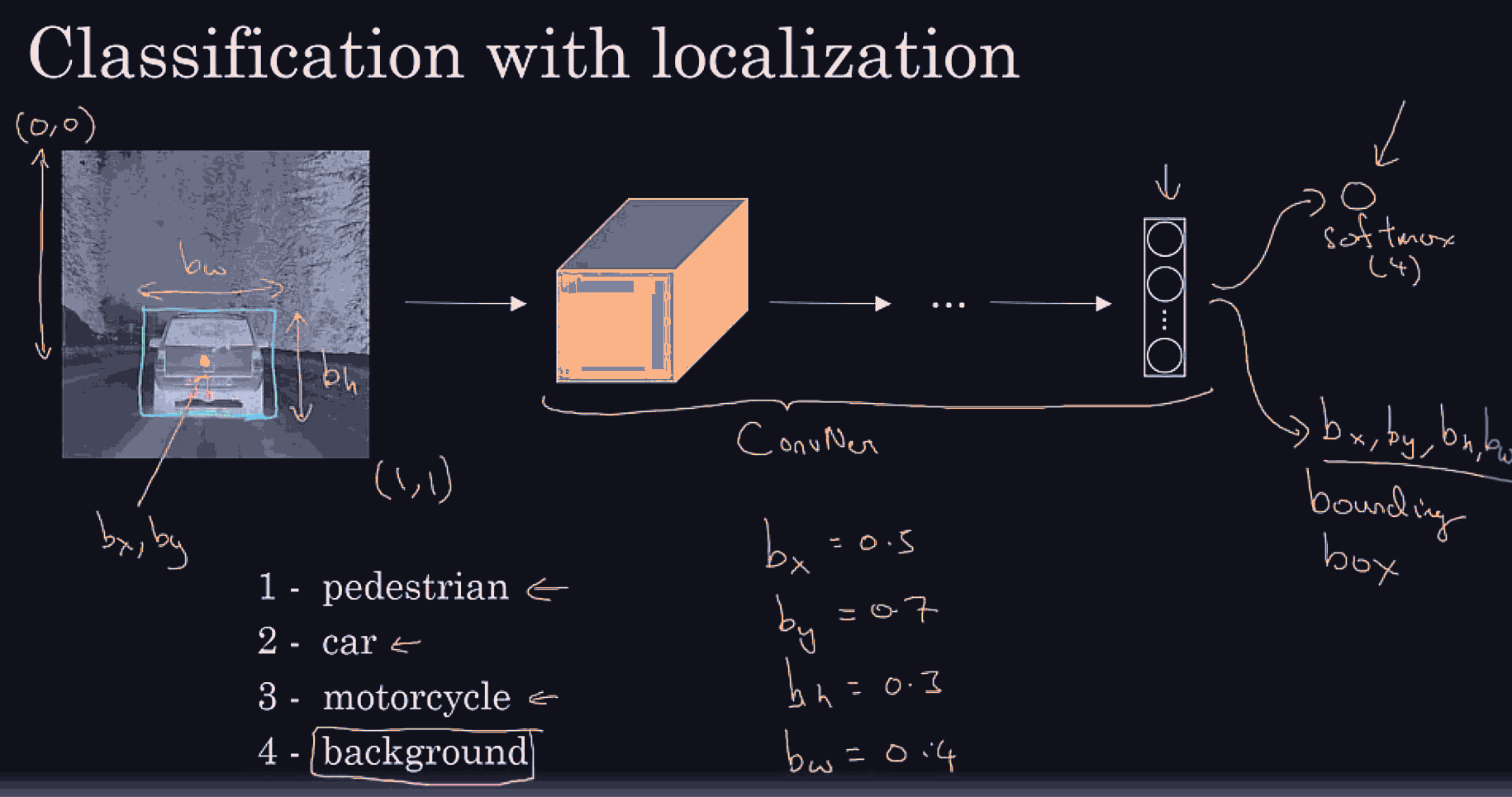
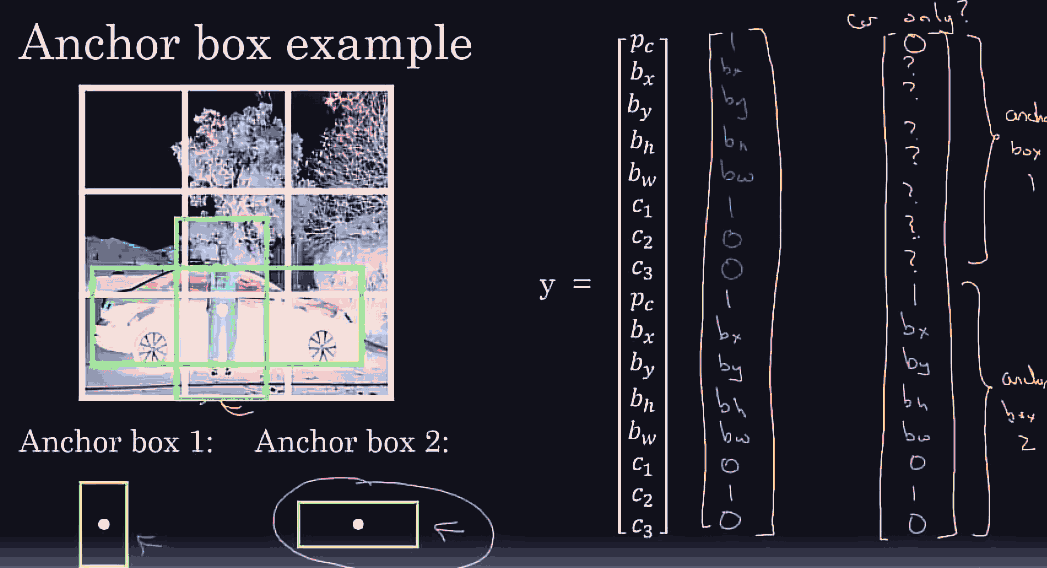
Essentially, in addition to a one hot vector that has pederstrain or car or motorcycle or background (remember localization means only 1 object) we might have 4 more (regressive-like) features, bx, by for the midpoint of the bounding box, and the bw for width, and bh for height, so this would allow us to supervise learn on these new ground truth vectors.
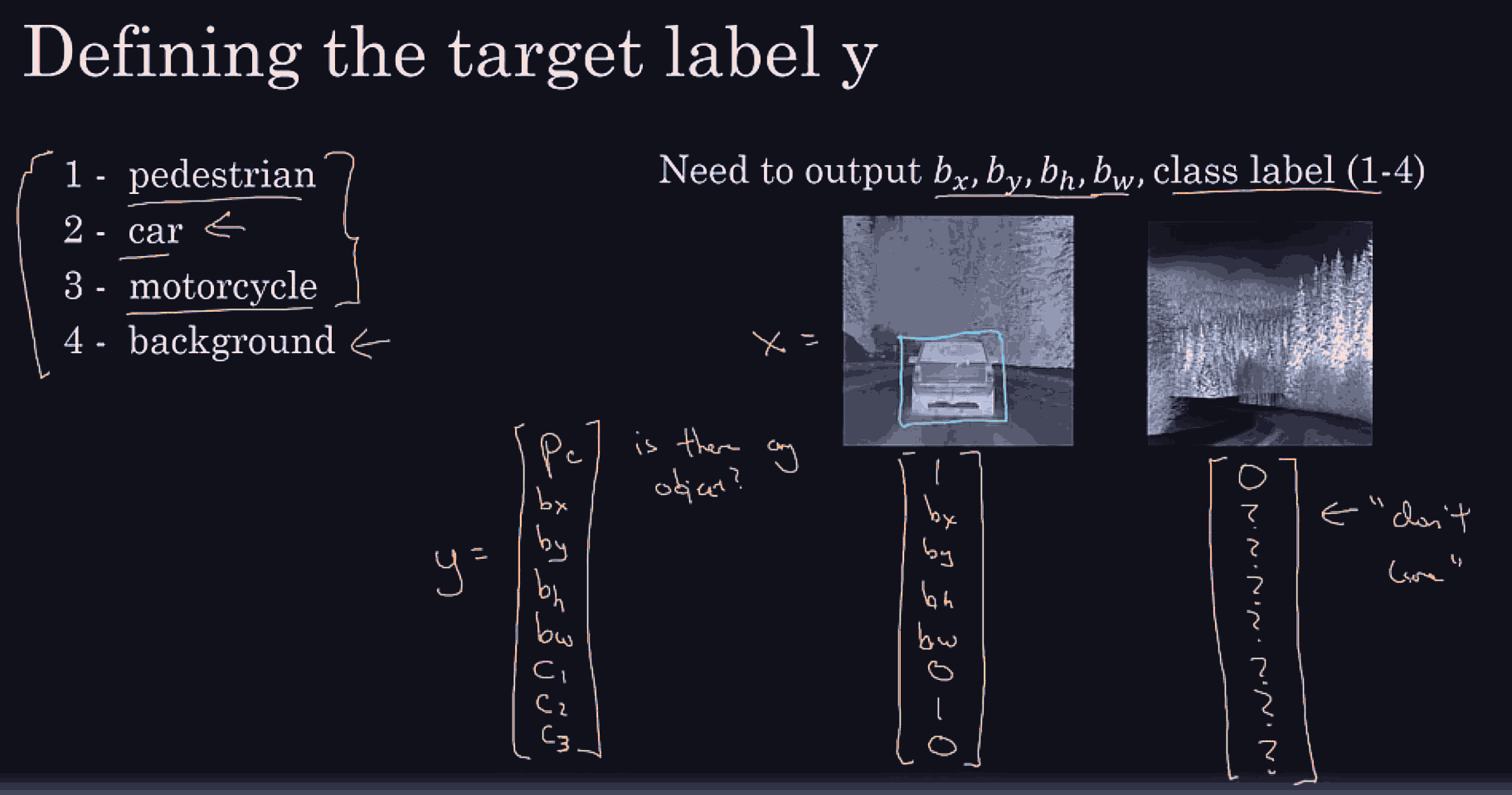
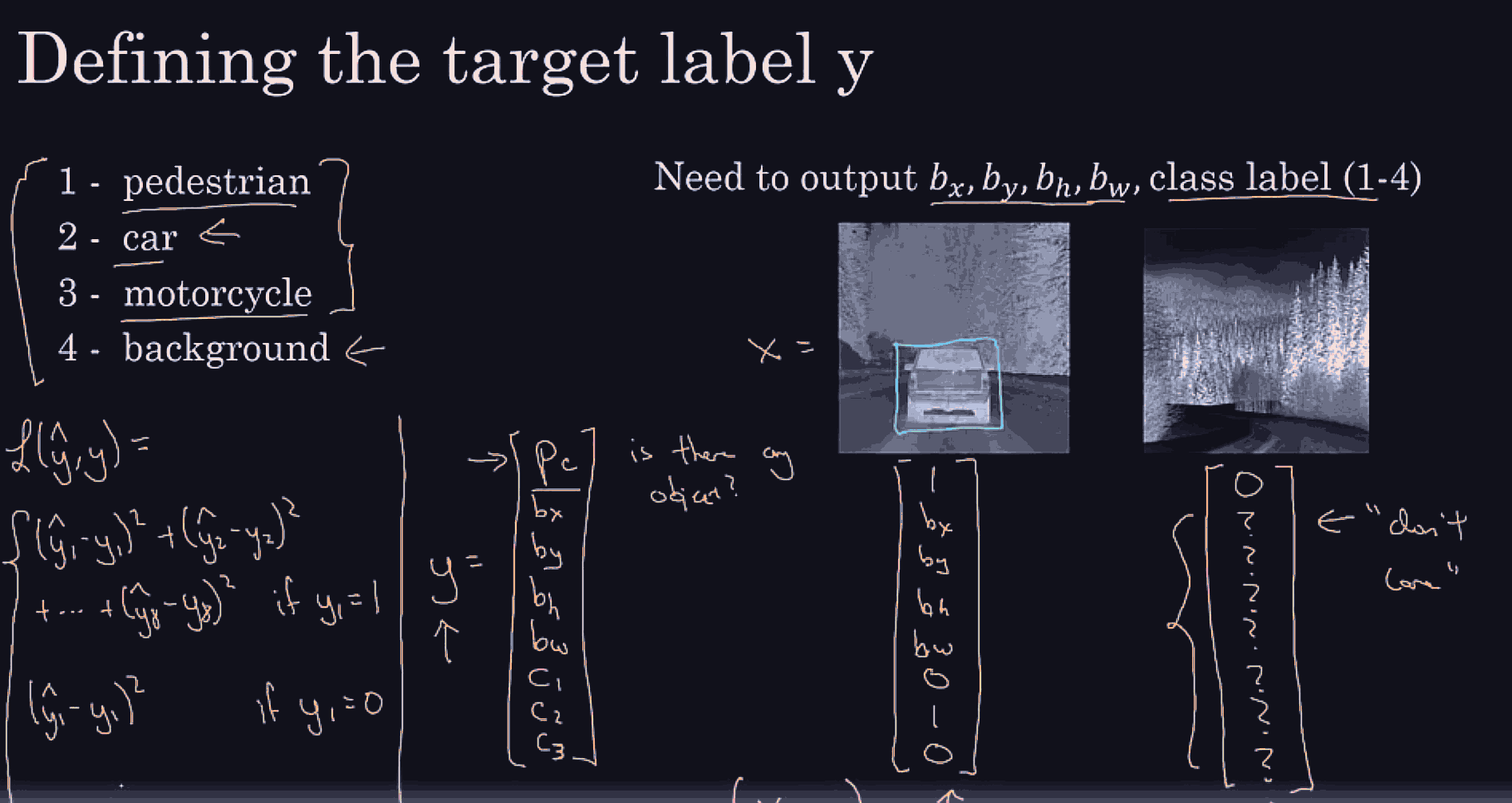

the labels and landmark positions must be consistent across all target vectors.
The next idea for detecting multiple objects is to roughly: train on closely cropped images and do classification. then use a sliding window, and train with localization too.



There is a large issue with computational cost, the sliding windows choosing the granularity, pushing each crop through a conv net, might take a mine ahha :)
![[Support/Figures/Pasted image 20241003050234.png#invert_B]]
The cool idea is, if our conv net specifically works on 14x14 images, we thing about 14x14 as out sliding window size!!!! then if we for example pass a 28x28,

better bounding boxes:
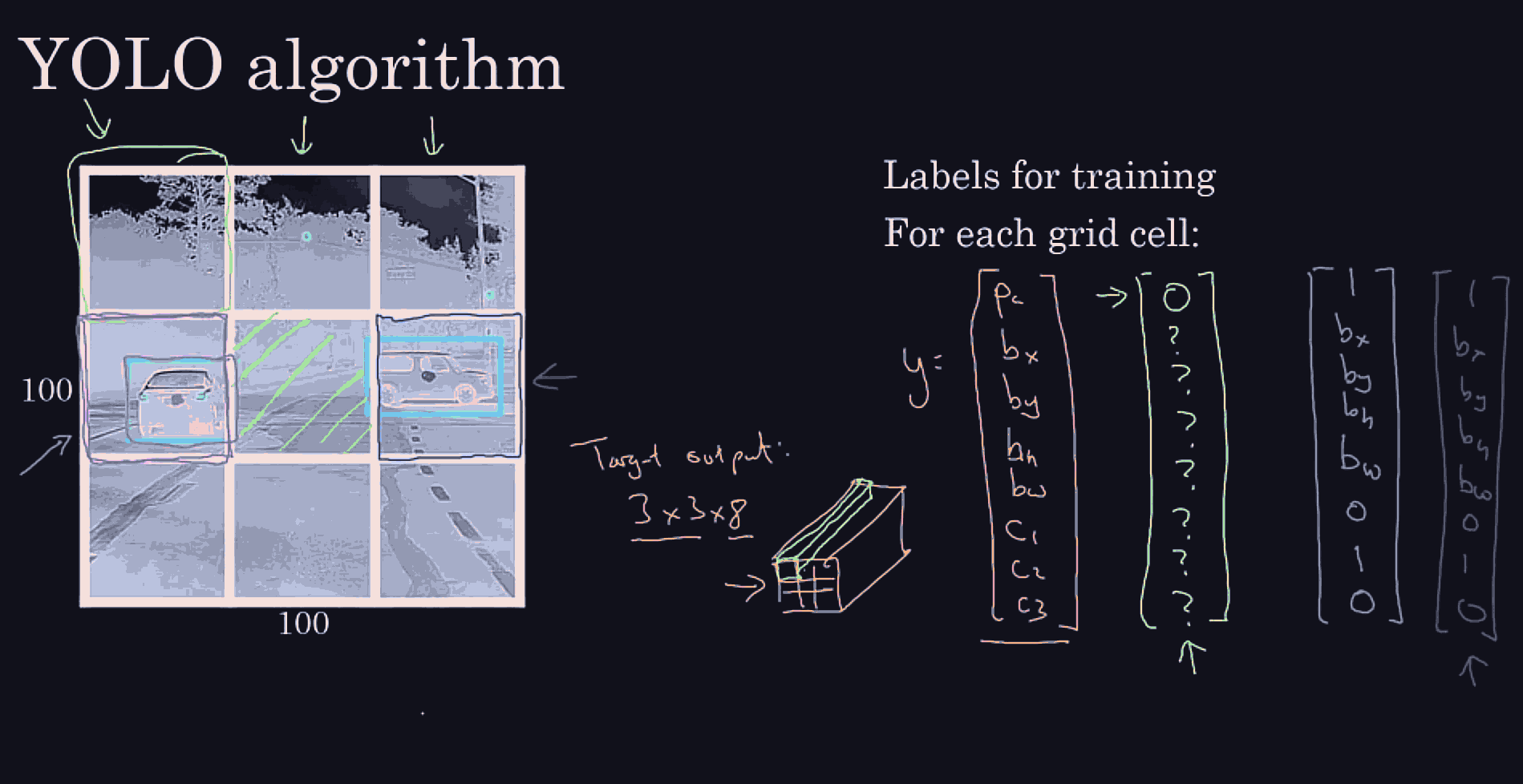
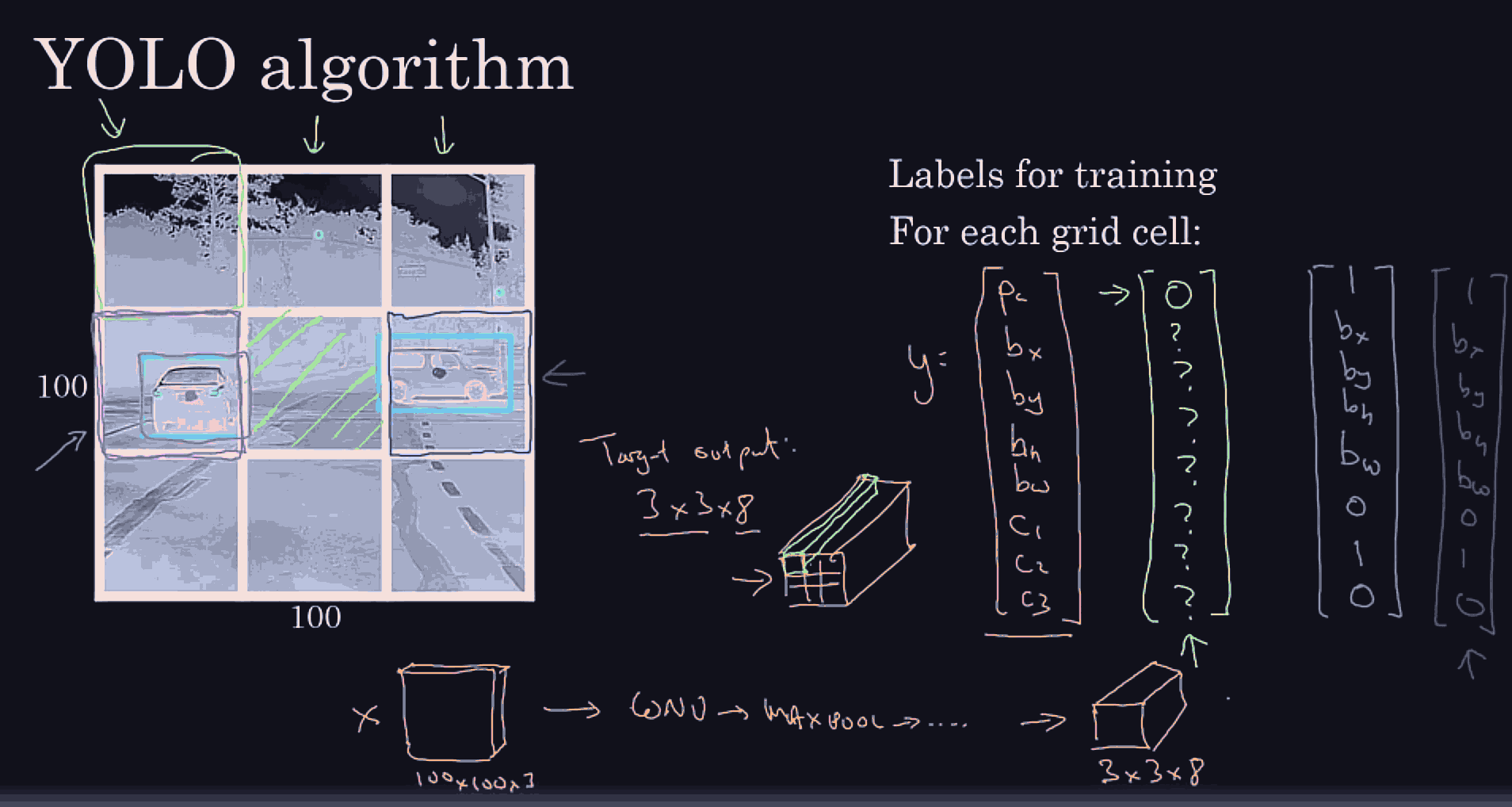
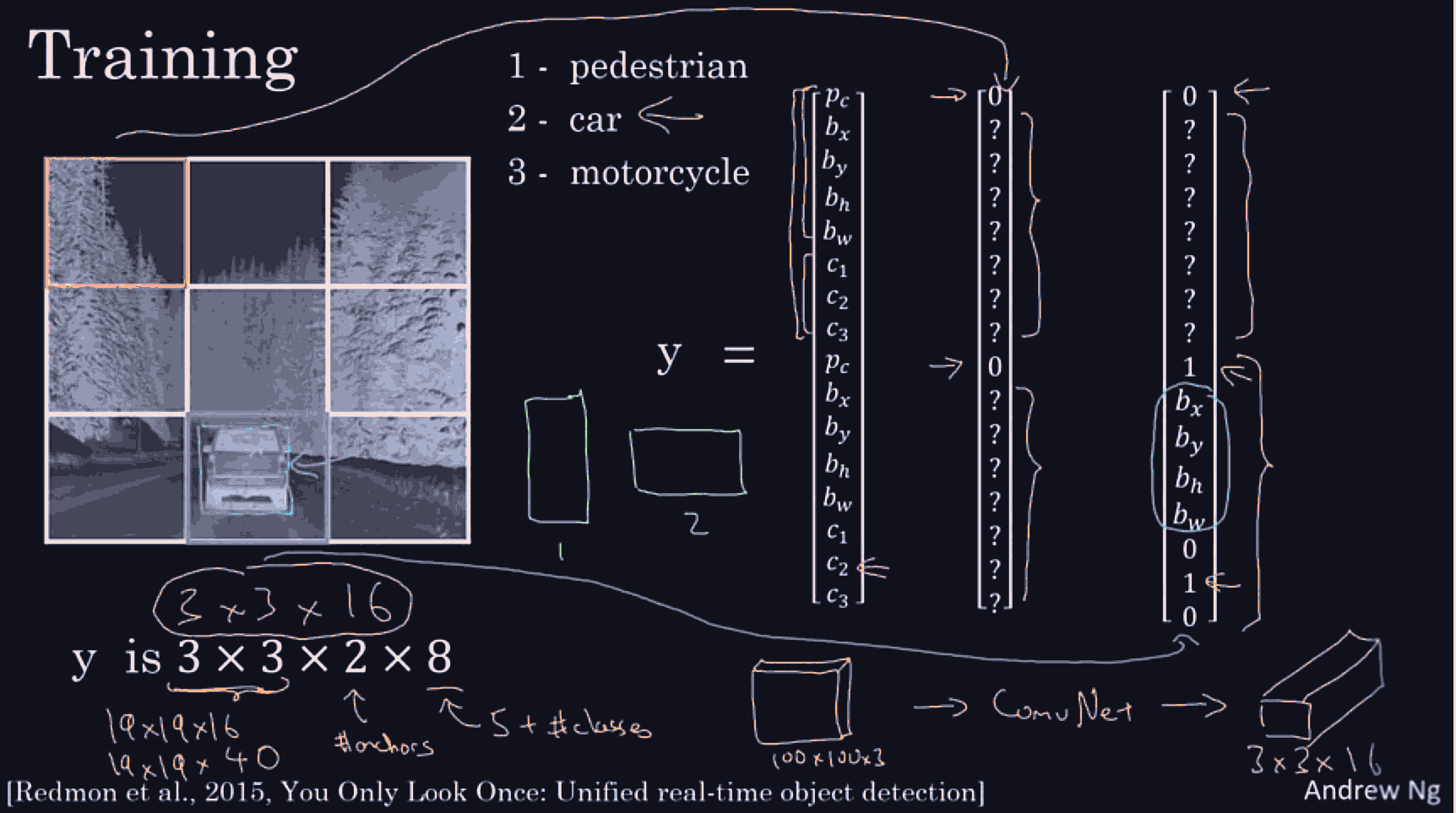
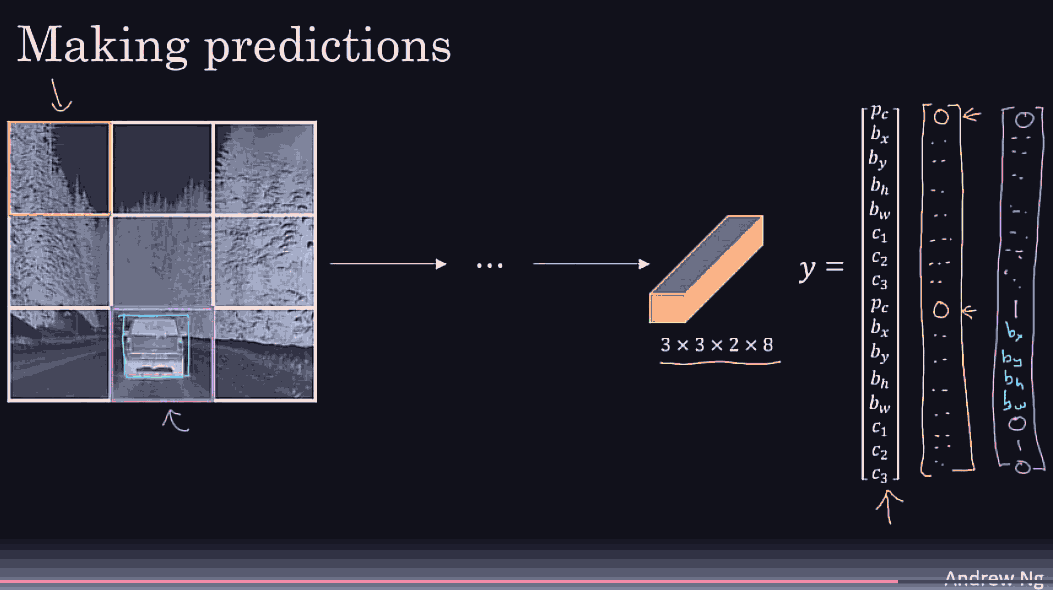
choose a reaosnoable grid size, in each grid cell we expect to have 1 object, repesetned by the bounding box midpoint. So those will be the target vector. even if the object spans multiple grid cells, if a grid cell is fine enough, the midpoint of each bounding box better be present in exactly one grid cell.


we might detect many grid cells, that have a car.

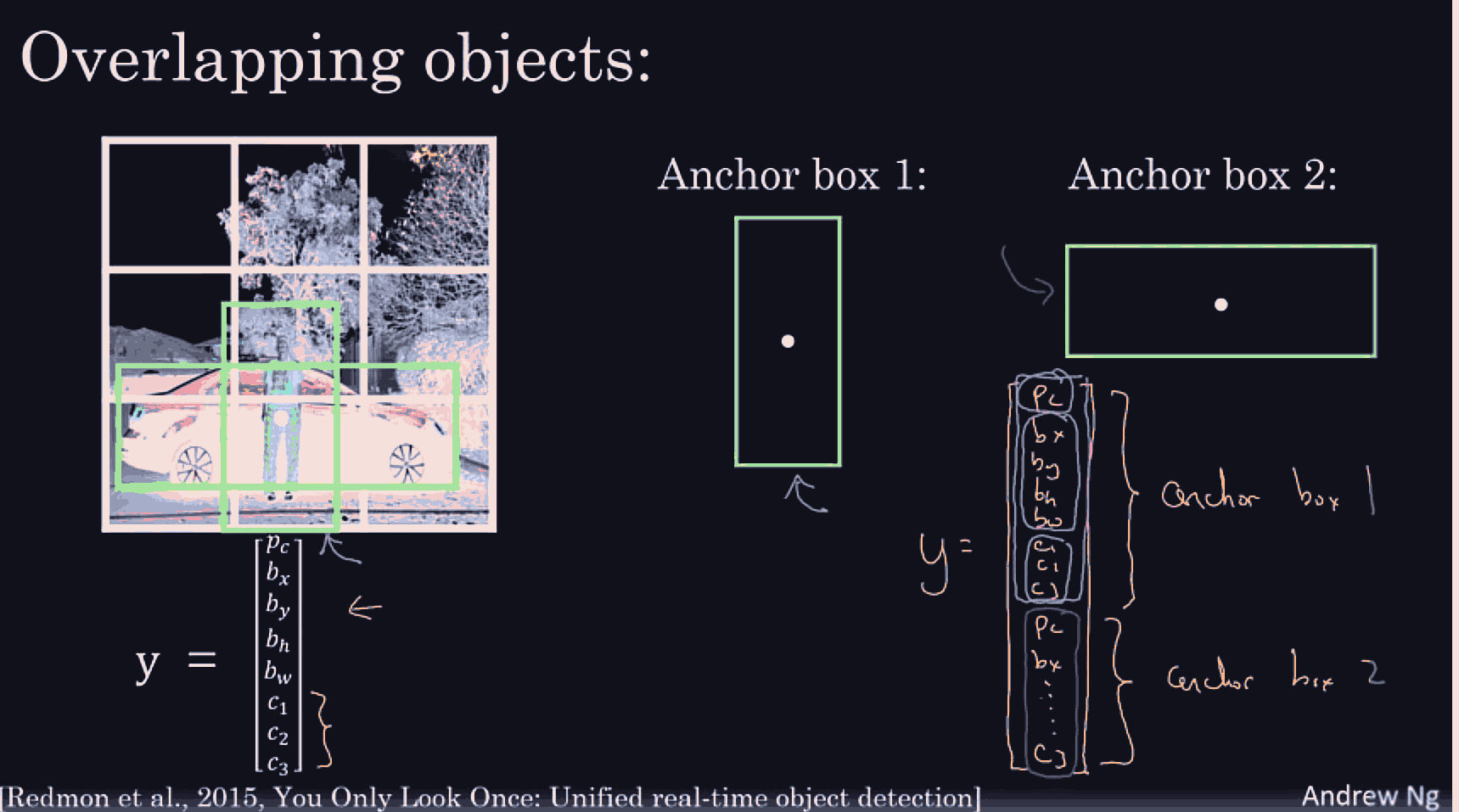




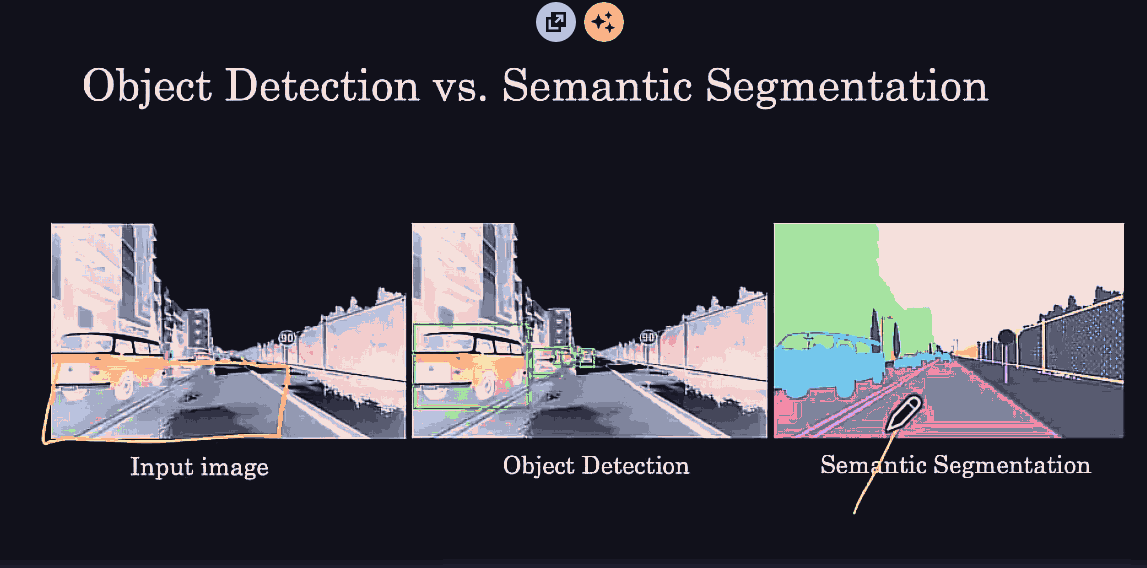


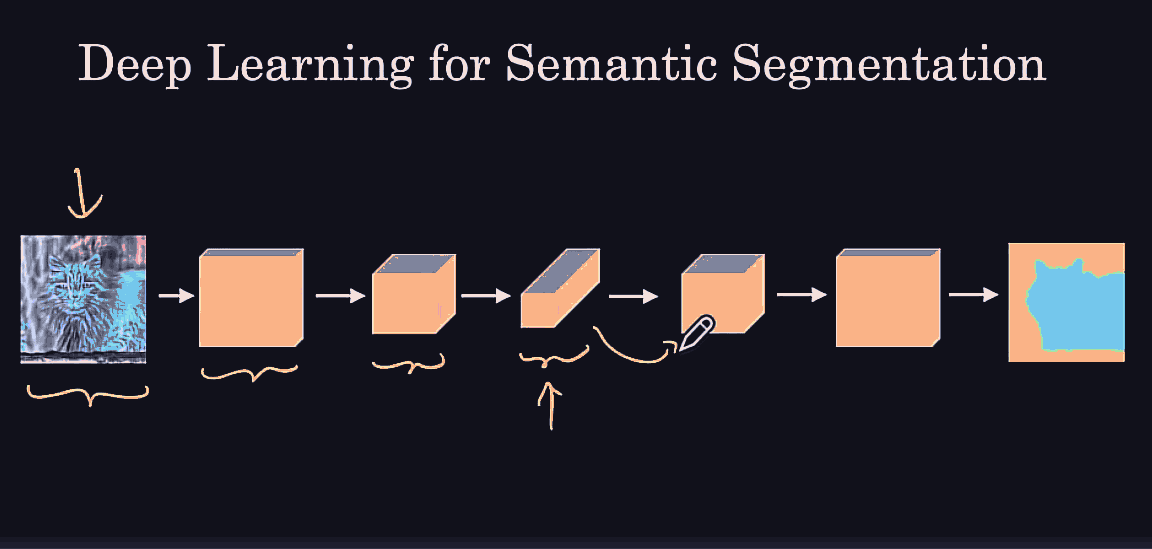
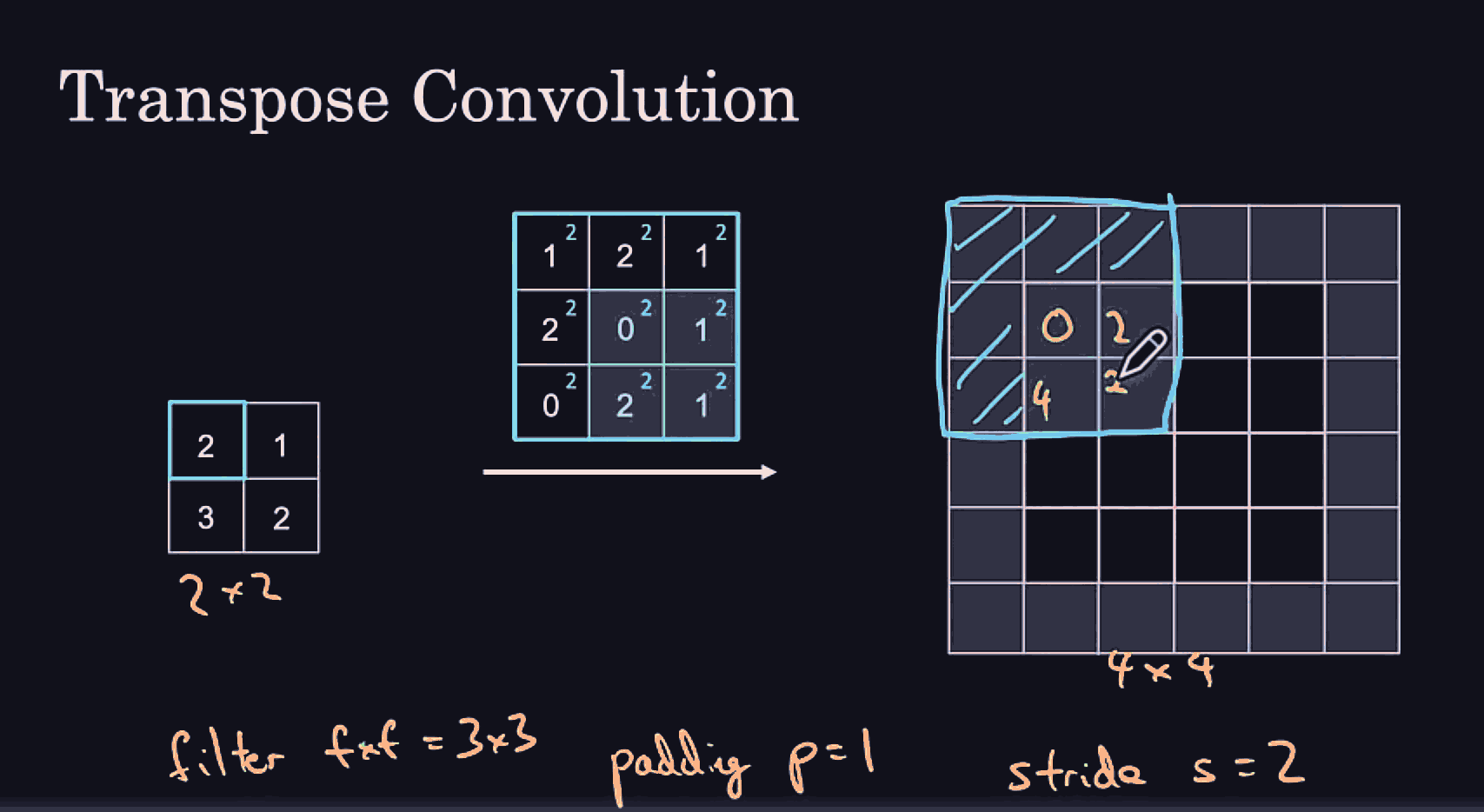
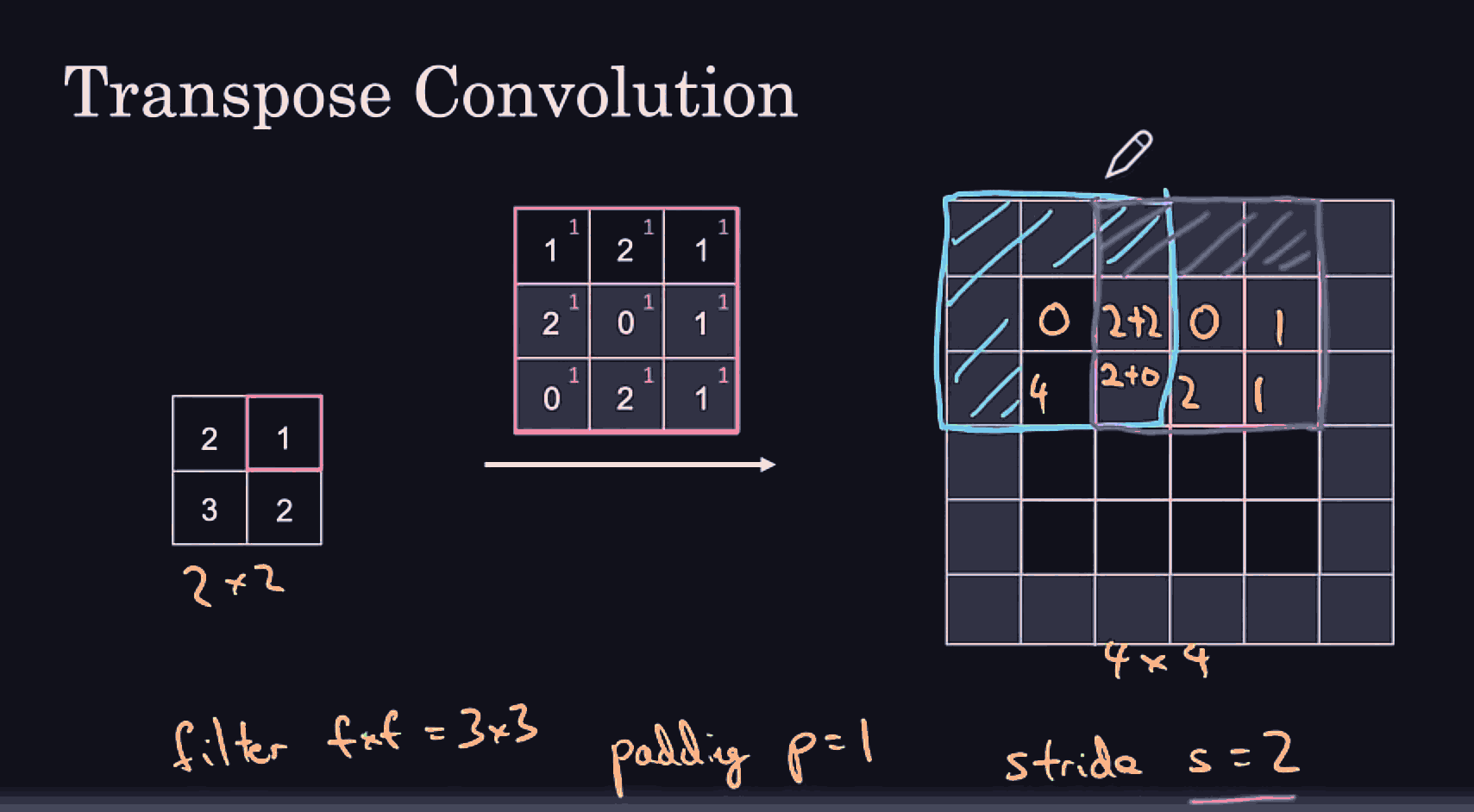
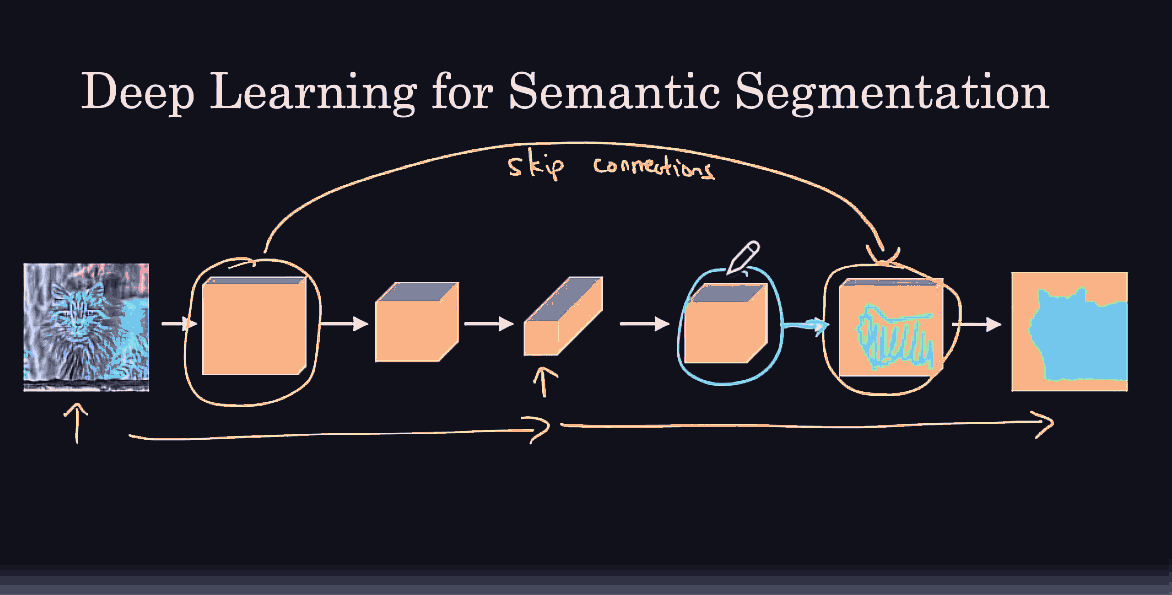
it might be useful to get more detailed/low level features from the leftmost hidden layer, as well as some higher level spatial/contextual features from the previous layer into the last hidden layer.