Suppose we had a collection of image, that is, it has rows of pixels, each row containing pixels. Suppose we want to build a binary classifier model that takes such images, and maps it into two classes { - cat , - not cat}.
First, we have to collect the pixel RGB value into a column vector. We do this by reading the image matrix left to right, top to bottom, say R then G then B, and so we have an input vector of dimension .
our training data will be pairs for . where only if is a cat, and otherwise.
so we will store both and as columns of matrices. $$X =\begin{bmatrix}
\vdots \ \ \ \ \vdots \ \ \ \dots \ \ \ \ \vdots \
x^1 \ x^2 \ \dots \ x^m \
\vdots \ \ \ \ \vdots \ \ \ \dots \ \ \ \ \vdots \
\end{bmatrix}$$
Notice that each is stored as a column vector, and each is also (a 1 dimensional) column vector.
A model for binary classification, could take in a weight vector and maybe do a linear regression . notice that (notice that we will use hat notation to depict model outputs)
But the issue then is, that we want to somehow capture/approximate the probability that is a cat. so we want . And so we want the output to be bounded in .
Here is where we use the sigmoid function $$\sigma(z) = \frac{1}{1+e^{-z}}$$
Our model is then $$ \hat{y}^i = \sigma(w^Tx^i + b) $$
Now, we need a loss function, . Such that the following properties hold: decreases as decreases, and it would be nice if is convex, as a function of the weights and bias. That way, no matter where we start, our gradient descent will find the global minimum.
We claim that is not a good choice, because of course decreases as gets closer to , but is not convex, as a function of the weights or bias.
It is sufficient to show that is not convex in the weights, as that would be bad enough. Fix . then $$ \mathscr L(w) = \bigg({\dfrac{1}{1+e^{-(w^Tx^i + b)}}- y^i}\bigg)^2$$
so if we fix all other weights except and parametrize it by then, $$\mathscr L(t) = \bigg(\frac{1}{1+ e^{-(x^i_{j}t + C)}} - y^i\bigg)^2$$
essentially, we have $$\mathscr L(t) =\bigg(\frac{1}{1+ ae^{-bt }} - c\bigg)^2 $$
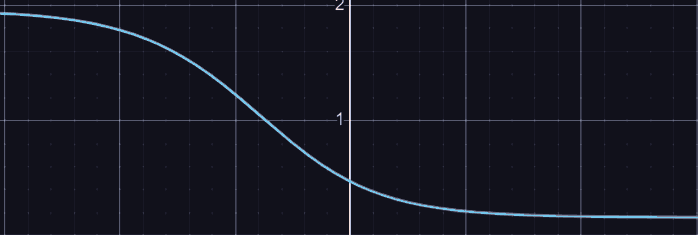
and we could of course evaluate the second derivative of , or we could look at the graph. (this for )
Notice that the left half is concave, with the function being above the secant line between any two points on the function.
A better loss function:
for a fixed and , it is pretty clear that depends on the weight vector , and bias .
in particular, for ease, let . and . Doing some algebra using: $$ \hat{y}^i = \frac{1}{1+ e^{-\Delta}} $$ we get: $$L(\Delta) = \log(e^{\Delta}+1) - c\Delta $$
Finally, we have, that for any weight in the weight vector, parametrizing and fixing all other weights, we have where is everything in the dot product of and that isn't times .
Essentially, . so $$L(t) = \log(e^{At + B} + 1) - c(At + B)$$
Hence, $$L'(t) = \frac{{Ae^Be^{At}}}{e^{At + B}+1} - cA$$
That is, $$L'(t) = A\bigg(\frac{{e^{At + B}}}{1 + e^{At + B}} - c\bigg)$$
Finally we see that is convex, with respect to every single weight.
notice that we had set to be the moving parameter, and fixed everything else. We could set any weight as the moving parameter and still obtain . Hence, the above inequality essentially says that for each . Hence, very informally, no matter in which axis (Imagine the loss function being , being plotted in dimensional space) we perturbate in, the rate of change of the function is increasing. This is especially nice because the whole point of gradient descent to initialize weights as a point then, the following algorithm: $$\text{for} \ j = 1 \ \text{to} \ n_{x} : w_{j} \leftarrow w_{j} - \frac{\alpha {\partial L}}{\partial w_{j}} $$ always finds the (one and only) well because is strictly convex with respect to each axis/weight .
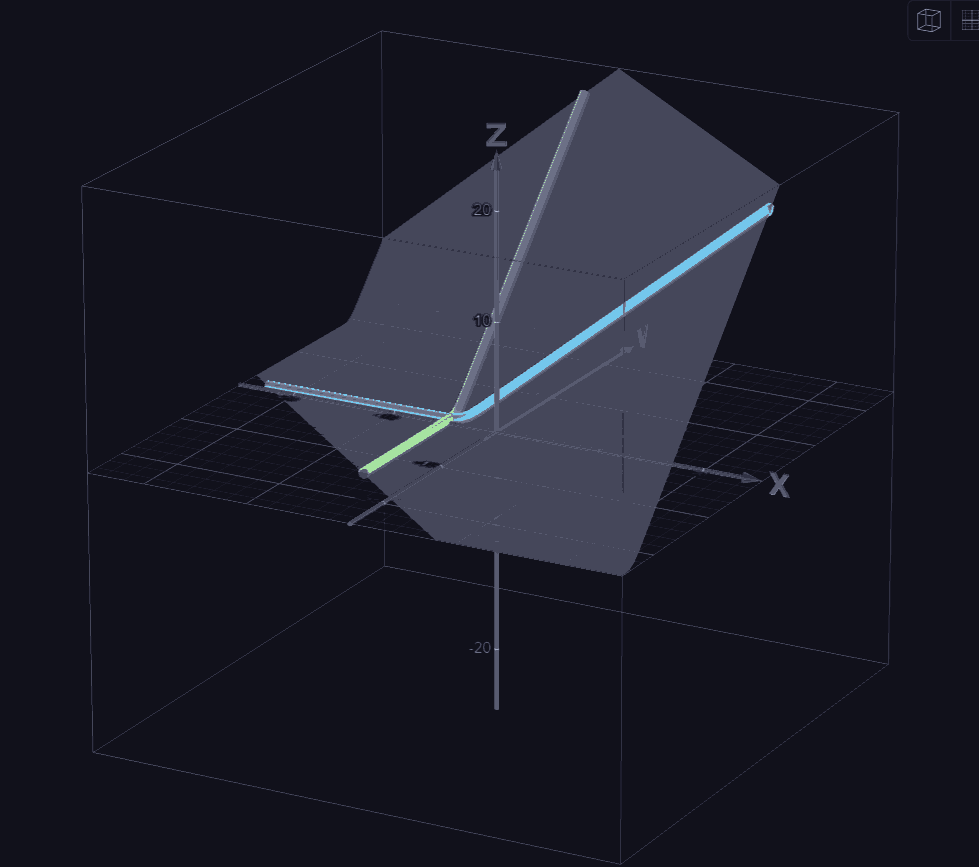
In general, the "well" idea can be seen in the graph of logistic regression with just two weights as the parameters.
![[Support/Figures/Pasted image 20240812223757.png]
here, just think about as weights, and as the loss function.
if we're restricted to we might start on any large and descend, noticing that as and decrease, the slope becomes less and less negative, becoming zero where the red and blue lines cross.
In practice we want to minimize the average loss of the model over the entire training set.
The cost function does this:
Indeed, the new algorithm for gradient descent then becomes:
where is the learning rate. Here, It's pretty self explanatory how to calculate the derivative of this "cost" function with respect to a weight: we simply accumulate the derivate of the loss function wrt to that weight for each training example. .
For the logistic regression model, let's figure out the backpropagation:
Where ,
Let's break this down:
One pattern we notice here is that we always take the derivative of an intermediate variable wrt to the immediately incoming input variable.
So we will just use as a placeholder to for the immediate incoming input variable, (IIIV)